Key Takeaways
- Agentic AI is the ability of machines to perform tasks requiring human intelligence, such as learning, decision-making, and problem-solving.
- Main branches of AI include Machine Learning, NLP, Computer Vision, Robotics, and Expert Systems, each unlocking different applications.
- Agentic AI is reshaping industries from healthcare and finance to contact centers by boosting efficiency and personalization.
- Ethical challenges like bias, transparency, and privacy remain central concerns as AI expands.
- Economic and social impacts include job displacement and inequality, but current evidence shows AI often enhances rather than eliminates roles.
- Risks range from misinformation and deepfakes to speculative existential risks tied to future AGI development.
- The future of AI raises open questions around control, alignment with human values, and specialized capabilities emerging from new platforms.
The term “artificial intelligence” was coined at the famous Dartmouth Conference in 1956, put on by luminaries like John McCarthy, Marvin Minsky, and Claude Shannon, among others.
These organizers wanted to create machines that “use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves.” They went on to claim that “…a significant advance can be made in one or more of these problems if a carefully selected group of scientists work on it together for a summer.”
Half a century later, it’s fair to say that this has not come to pass; brilliant as they were, it would seem as though McCarthy et al. underestimated how difficult it would be to scale the heights of the human intellect.
Nevertheless, remarkable advances have been made over the past decade, so much so that they’ve ignited a firestorm of controversy around this technology. People are questioning the ways in which it can be used negatively, and whether it might ultimately pose an extinction risk to humanity; they’re probing fundamental issues around whether machines can be conscious, exercise free will, and think in the way a living organism does; they’re rethinking the basis of intelligence, concept formation, and what it means to be human.
These are deep waters to be sure, and we’re not going to swim them all today. But as contact center managers and others begin the process of thinking about using AI, it’s worth being at least aware of what this broader conversation is about. It will likely come up in meetings, in the press, or in Slack channels in exchanges between employees.
And that’s the subject of our piece today. We’re going to start by asking what artificial intelligence is and how it’s being used, before turning to address some of the concerns about its long-term potential. Our goal is not to answer all these concerns, but to make you aware of what people are thinking and saying.
What is Artificial Intelligence?
Artificial intelligence is famous for having many, many definitions. There are those, for example, who believe that in order to be intelligent, computers must think like humans, and those who reply that we didn’t make airplanes by designing them to fly like birds.
For our part, we prefer to sidestep the question somewhat by utilizing the approach taken in one of the leading textbooks in the field, Stuart Russell and Peter Norvig’s “Artificial Intelligence: A Modern Approach”.
They propose a multi-part system for thinking about different approaches to AI. One set of approaches is human-centric and focuses on designing machines that either think like humans – i.e., engage in analogous cognitive and perceptual processes – or act like humans – i.e., by behaving in a way that’s indistinguishable from a human, regardless of what’s happening under the hood (think: the Turing Test).
The other set of approaches is ideal-centric and focuses on designing machines that either think in a totally rational way – conformant with the rules of Bayesian epistemology, for example – or behave in a totally rational way – utilizing logic and probability, but also acting instinctively to remove itself from danger, without going through any lengthy calculations.
From a practical standpoint, AI can also be defined as the ability of machines to perform tasks that normally require human intelligence, such as learning, problem-solving, and decision-making. AI systems learn from data to identify patterns and make predictions.
Main branches of AI include:
- Agentic AI: refers to artificial intelligence systems capable of taking autonomous, goal-directed actions rather than simply responding to inputs.
- Machine Learning (ML): algorithms that improve performance over time with data.
- Natural Language Processing (NLP): enables human-computer interaction through text and speech.
- Computer Vision: powers machines to interpret and analyze visual data.
- Robotics: supports autonomous systems that perform tasks in the physical world.
- Expert Systems: encode domain-specific knowledge for decision-making.
What we have here, in other words, is a framework. Using the framework not only gives us a way to think about almost every AI project in existence, it also saves us from needing to spend all weekend coming up with a clever new definition of AI.
Joking aside, we think this is a productive lens through which to view the whole debate, and we offer it here for your information.
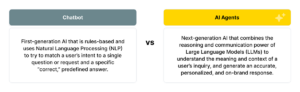
How Does Agentic AI Differ From Traditional AI?
Traditional AI systems were designed to perform specific, rule-based tasks like predicting loan defaults or detecting spam emails. They rely on structured data and follow defined parameters to reach a decision.
Agentic AI, however, represents a new frontier. Instead of merely analyzing data, it creates new data, producing text, code, images, or audio that mimic human expression. These models learn from massive datasets to understand structure, style, and context, allowing them to generate entirely original outputs.
This distinction matters because agentic AI expands the role of machines from assistive tools to creative collaborators.
- In contact centers, it drafts responses, summarizes conversations, and adapts to tone.
- In marketing, it generates campaigns and copy tailored to audiences.
- In software, it writes or optimizes code in seconds.
Agentic AI doesn’t replace human creativity; it scales it. It can handle repetitive cognitive work so humans can focus on judgment, empathy, and innovation.
What Are the Limitations of AI?
AI’s potential is vast, but it has clear and important limitations.
Despite its sophistication, AI still struggles with context, common sense, and abstract reasoning. A model can produce coherent text or make accurate predictions, but it doesn’t understand the world the way humans do.
Key Limitations Include:
- Lack of true comprehension: AI interprets patterns, not meaning.
- Dependence on data quality: Poor or biased data leads to flawed outputs.
- Limited adaptability: Most models perform poorly outside their training domain.
- Ethical blind spots: AI has no intrinsic moral compass or emotional intelligence.
For contact centers and other industries, this means AI should be used as a co-pilot, not a substitute for human decision-making. The best outcomes come from combining machine efficiency with human empathy and oversight.
Who Is Accountable When AI Makes a Mistake?
Accountability is one of the thorniest questions in AI ethics. If an algorithm makes a wrong decision denying a loan, misclassifying a medical image, or providing biased recommendations, who bears the blame?
Is it the developer who built the system, the organization that deployed it, or the AI itself?
At present, humans remain fully accountable. AI is a tool, not an entity capable of responsibility. That’s why governance and transparency are critical. Companies deploying AI should: Maintain human oversight in high-stakes decisions. Establish audit trails that document how outputs are produced. Implement explainability features to clarify reasoning. Define escalation protocols when AI outputs seem unreliable.
Ultimately, the ethical principle is simple: AI assists, but humans decide. As AI becomes more capable, accountability frameworks must evolve in parallel to ensure technology remains under human control.
How Can We Prevent AI Bias?
Bias is one of AI’s most persistent and challenging problems. When AI systems are trained on biased or incomplete data, they can unintentionally replicate or even amplify human prejudice.
In sectors like hiring, law enforcement, or lending, these biases can have real-world consequences. For contact centers, bias can subtly affect how language models interpret tone or prioritize customer queries.
Strategies to Reduce Bias:
- Use diverse, representative training data. Ensure datasets reflect varied demographics, dialects, and contexts.
- Conduct regular bias audits. Test models under different conditions and measure fairness outcomes.
- Include human review. Use human judgment in quality assurance loops to catch biased outputs.
- Apply explainability tools. Tools like SHAP and LIME help visualize how models make decisions.
- Adopt ethical AI frameworks. Follow established standards like NIST’s AI Risk Management Framework or ISO/IEC 42001.
Bias prevention isn’t about perfection; it’s about constant vigilance. AI must evolve alongside our understanding of fairness and equity.
What is Artificial Intelligence Good For?
Given all the hype around ChatGPT, this might seem like a quaint question. But not that long ago, many people were asking it in earnest. The basic insights upon which large language models like ChatGPT are built go back to the 1960s, but it wasn’t until 1) vast quantities of data became available, and 2) compute cycles became extremely cheap that much of its potential was realized.
Today, large language models are changing (or poised to change) many different fields. Our audience is focused on contact centers, so that’s what we’ll focus on as well.
There are a number of ways that agentic AI is changing contact centers. Because of its remarkable abilities with natural language, it’s able to dramatically speed up agents in their work by answering questions and formatting replies. These same abilities allow it to handle other important tasks, like summarizing articles and documentation and parsing the sentiment in customer messages to enable semi-automated prioritization of their requests.
Though we’re still in the early days, the evidence so far suggests that large language models like Quiq’s agentic ai platform will do a lot to increase the efficiency of contact center agents.
Beyond contact centers, AI is transforming healthcare (diagnostics, drug discovery), finance (fraud detection, algorithmic trading), transportation (autonomous vehicles), and education (personalized learning). Its flexibility is why AI is considered one of the most impactful technologies across industries.
Will AI be Dangerous?
One thing that’s burst into public imagination recently has been the debate around the risks of artificial intelligence, which fall into two broad categories.
The first category is what we’ll call “social and political risks”. These are the risks that large language models will make it dramatically easier to manufacture propaganda at scale, and perhaps tailor it to specific audiences or even individuals. When combined with the astonishing progress in deepfakes, it’s not hard to see how there could be real issues in the future. Most people (including us) are poorly equipped to figure out when a video is fake, and if the underlying technology gets much better, there may come a day when it’s simply not possible to tell.
Political operatives are already quite skilled at cherry-picking quotes and stitching together soundbites into a damning portrait of a candidate – imagine what’ll be possible when they don’t even need to bother.
But the bigger (and more speculative) danger is around really advanced artificial intelligence. Because this case is harder to understand, it’s what we’ll spend the rest of this section on.
Artificial Superintelligence and Existential Risk
As we understand it, the basic case for existential risk from artificial intelligence goes something like this:
“Someday soon, humanity will build or grow an artificial general intelligence (AGI). It’s going to want things, which means that it’ll be steering the world in the direction of achieving its ambitions. Because it’s smart, it’ll do this quite well, and because it’s a very alien sort of mind, it’ll be making moves that are hard for us to predict or understand. Unless we solve some major technological problems around how to design reward structures and goal architectures in advanced agentive systems, what it wants will almost certainly conflict in subtle ways with what we want. If all this happens, we’ll find ourselves in conflict with an opponent unlike any we’ve faced in the history of our species, and it’s not at all clear we’ll prevail.”
This is heady stuff, so let’s unpack it bit by bit. The opening sentence, “…humanity will build or grow an artificial general intelligence”, was chosen carefully. If you understand how LLMs and deep learning systems are trained, the process is more akin to growing an enormous structure than it is to building one.
This has a few implications. First, their internal workings remain almost completely inscrutable. Though researchers in fields like mechanistic interpretability are going a long way toward unpacking how neural networks function, the truth is, we’ve still got a long way to go.
What this means is that we’ve built one of the most powerful artifacts in the history of Earth, and no one is really sure how it works.
Another implication is that no one has any good theoretical or empirical reason to bound the capabilities and behavior of future systems. The leap from GPT-2 to GPT-3.5 was astonishing, as was the leap from GPT-3.5 to GPT-4. The basic approach so far has been to throw more data and more compute at the training algorithms; it’s possible that this paradigm will begin to level off soon, but it’s also possible that it won’t. If the gap between GPT-4 and GPT-5 is as big as the gap between GPT-3 and GPT-4, and if the gap between GPT-6 and GPT-5 is just as big, it’s not hard to see that the consequences could be staggering.
As things stand, it’s anyone’s guess how this will play out. But that’s not necessarily a comforting thought.
Next, let’s talk about pointing a system at a task. Does ChatGPT want anything? The short answer is: as far as we can tell, it doesn’t. ChatGPT isn’t an agent, in the sense that it’s trying to achieve something in the world, but work into agentive systems is ongoing. Remember that 10 years ago most neural networks were basically toys, and today we have ChatGPT. If breakthroughs in agency follow a similar pace (and they very well may not), then we could have systems able to pursue open-ended courses of action in the real world in relatively short order.
Another sobering possibility is that this capacity will simply emerge from the training of huge deep learning systems. This is, after all, the way human agency emerged in the first place. Through the relentless grind of natural selection, our ancestors went from chipping flint arrowheads to industrialization, quantum computing, and synthetic biology.
To be clear, this is far from a foregone conclusion, as the algorithms used to train large language models are quite different from natural selection. Still, we want to relay this line of argumentation, because it comes up a lot in these discussions.
Finally, we’ll address one more important claim, “…what it wants will almost certainly conflict in subtle ways with what we want.” Why do we think this is true? Aren’t these systems that we design and, if so, can’t we just tell it what we want it to go after?
Unfortunately, it’s not so simple. Whether you’re talking about reinforcement learning or something more exotic like evolutionary programming, the simple fact is that our algorithms often find remarkable mechanisms by which to maximize their reward in ways we didn’t intend.
There are thousands of examples of this (ask any reinforcement-learning engineer you know), but a famous one comes from the classic Coast Runners video game. The engineers who built the system tried to set up the algorithm’s rewards so that it would try to race a boat as well as it could. What it actually did, however, was maximize its reward by spinning in a circle to hit a set of green blocks over and over again.

Now, this may seem almost silly – do we really have anything to fear from an algorithm too stupid to understand the concept of a “race”?
But this would be missing the thrust of the argument. If you had access to a superintelligent AI and asked it to maximize human happiness, what happened next would depend almost entirely on what it understood “happiness” to mean.
If it were properly designed, it would work in tandem with us to usher in a utopia. But if it understood it to mean “maximize the number of smiles”, it would be incentivized to start paying people to get plastic surgery to fix their faces into permanent smiles (or something similarly unintuitive).
Does AI Pose an Existential Risk?
Above, we’ve briefly outlined the case that sufficiently advanced AI could pose a serious risk to humanity by being powerful, unpredictable, and prone to pursuing goals that weren’t-quite-what-we-meant.
So, does this hold water? Honestly, it’s too early to tell. The argument has hundreds of moving parts, some well-established and others much more speculative. Our purpose here isn’t to come down on one side of this debate or the other, but to let you know (in broad strokes) what people are saying.
At any rate, we are confident that the current version of ChatGPT doesn’t pose any existential risks. On the contrary, it could end up being one of the greatest advancements in productivity ever seen in contact centers. And that’s what we’d like to discuss in the next section.
What is the Biggest Concern with AI?
Ethical Challenges
While AI’s potential is vast, so are the concerns surrounding its rapid advancement. One of the most pressing concerns is the ethical challenge of transparency. AI models often operate as “black boxes,” making decisions without clear explanations. This lack of visibility raises concerns about hidden biases that can lead to unfair or even discriminatory outcomes, especially in areas like hiring, lending, and law enforcement.
Economic Ramifications
Beyond ethics, AI’s economic impact is another major concern: automation is reshaping entire industries. While it creates new opportunities, it also threatens traditional jobs, particularly in sectors reliant on repetitive tasks. This shift could complicate wealth disparities, favoring companies and individuals who own or develop AI technologies while leaving others behind.
The bigger conversation is whether AI will replace humans or serve as a “copilot.” Current evidence suggests AI is enhancing productivity by supporting humans rather than replacing them outright.
Social Impacts
On a broader scale, AI’s social implications are hard to ignore. The displacement of jobs, increasing socio-economic inequality, and reduced human oversight in decision-making all point to a future where AI plays an even greater role in shaping society. This raises questions about the balance between automation and human oversight.
Privacy and data security are also critical concerns, since AI requires massive datasets to function. Without safeguards, personal data could be misused or breached.
Will AI Take All the Jobs?
The concern that someday a new technology will render human labor obsolete is hardly new. It was heard when mechanized weaving machines were created, when computers emerged, when the internet emerged, and when ChatGPT came onto the scene.
We’re not economists and we’re not qualified to take a definitive stand, but we do have some early evidence that is showing that large language models are not only not resulting in layoffs, they’re making agents much more productive.
Erik Brynjolfsson, Danielle Li, and Lindsey R. Raymond, three MIT economists, looked at the ways in which generative AI was being used in a large contact center. They found that it was actually doing a good job of internalizing the ways in which senior agents were doing their jobs, which allowed more junior agents to climb the learning curve more quickly and perform at a much higher level. This had the knock-on effect of making them feel less stressed about their work, thus reducing turnover.
Now, this doesn’t rule out the possibility that GPT-10 will be the big job killer. But so far, large language models are shaping up to be like every prior technological advance, i.e., increasing employment rather than reducing it.
AI is more likely to shift job responsibilities than eliminate them entirely. By automating repetitive tasks, it frees workers to focus on higher-value skills like problem-solving, empathy, and creativity. In contact centers, for example, AI helps agents train faster, reduce stress, and improve retention.
What is the Future of AI?
The rise of AI is raising stock valuations, raising deep philosophical questions, and raising expectations and fears about the future. We don’t know for sure how all this will play out, but we do know contact centers, and we know that they stand to benefit greatly from the current iteration of large language models.
These tools are helping agents answer more queries per hour, do so more thoroughly, and make for a better customer experience in the process.
If you want to get in on the action, set up a demo of our technology today.
Frequently Asked Questions (FAQs)
What is artificial intelligence in simple terms?
AI is when machines can perform tasks that normally require human intelligence, like learning, analyzing data, making predictions, or interacting with people.
What are the main types of AI?
The core branches include Machine Learning, Natural Language Processing, Computer Vision, Robotics, and Expert Systems. Each serves a different purpose.
How does AI actually work?
AI systems are trained on data, which they use to detect patterns and make predictions. Machine Learning enables them to improve over time as they’re exposed to more data.
What are the biggest risks of AI today?
Key concerns include bias in decision-making, lack of transparency (“black box” models), privacy issues, misinformation and deepfakes, and potential job displacement.
Will AI take all the jobs?
Most evidence shows AI acts as a “copilot” that boosts productivity rather than replacing workers outright. It automates repetitive tasks while humans focus on higher-value work.
What’s the future of AI?
People are asking how powerful AI will become, whether it can be controlled safely, and how to align it with human values.