Artificial intelligence tools like ChatGPT are changing the way strategists are building their brands.
But with the staggering rate of change in the field, it can be hard to know how to utilize its full potential. Should you hire an engineering team? Pay for a subscription and do it yourself?
The truth is, it depends. But one thing you can try is prompt engineering, a term that refers to carefully crafting the instructions you give to the AI to get the best possible results.
In this piece, we’ll cover the basics of prompt engineering and discuss the many ways in which you can build your brand voice with generative AI.
What is Prompt Engineering?
As the name implies, generative AI refers to any machine learning (ML) model whose primary purpose is to generate some output. There are generative AI applications for creating new images, text, code, and music.
There are also ongoing efforts to expand the range of outputs generative models can handle, such as a fascinating project to build a high-level programming language for creating new protein structures.
The way you get output from a generative AI model is by prompting it. Just as you could prompt a friend by asking “How was your vacation in Japan,” you can prompt a generative model by asking it questions and giving it instructions. Here’s an example:
“I’m working on learning Java, and I want you to act as though you’re an experienced Java teacher. I keep seeing terms like `public class` and `public static void`. Can you explain to me the different types of Java classes, giving an example and explanation of each?”
When we tried this prompt with GPT-4, it responded with a lucid breakdown of different Java classes (i.e., static, inner, abstract, final, etc.), complete with code snippets for each one.
When Small Changes Aren’t So Small
Mapping the relationship between human-generated inputs and machine-generated outputs is what the emerging field of “prompt engineering” is all about.
Prompt engineering only entered popular awareness in the past few years, as a direct consequence of the meteoric rise of large language models (LLMs). It rapidly became obvious that GPT-3.5 was vastly better than pretty much anything that had come before, and there arose a concomitant interest in the best ways of crafting prompts to maximize the effectiveness of these (and similar) tools.
At first glance, it may not be obvious why prompt engineering is a standalone profession. After all, how difficult could it be to simply ask the computer to teach you Chinese or explain a coding concept? Why have a “prompt engineer” instead of a regular engineer who sometimes uses GPT-4 for a particular task?
A lot could be said in reply, but the big complication is the fact that a generative AI’s output is extremely dependent upon the input it receives.
An example pulled from common experience will make this clearer. You’ve no doubt noticed that when you ask people different kinds of questions you elicit different kinds of responses. “What’s up?” won’t get the same reply as “I notice you’ve been distant recently, does that have anything to do with losing your job last month?”
The same basic dynamic applies to LLMs. Just as subtleties in word choice and tone will impact the kind of interaction you have with a person, they’ll impact the kind of interaction you have with a generative model.
All this nuance means that conversing with your fellow human beings is a skill that takes a while to develop, and that also holds in trying to productively using LLMs. You must learn to phrase your queries in a way that gives the model good context, includes specific criteria as to what you’re looking for in a reply, etc.
Honestly, it can feel a little like teaching a bright, eager intern who has almost no initial understanding of the problem you’re trying to get them to solve. If you give them clear instructions with a few examples they’ll probably do alright, but you can’t just point them at a task and set them loose.
We’ll have much more to say about crafting the kinds of prompts that help you build your brand voice in upcoming sections, but first, let’s spend some time breaking down the anatomy of a prompt.
This context will come in handy later.
What’s In A Prompt?
In truth, there are very few real restrictions on how you use an LLM. If you ask it to do something immoral or illegal it’ll probably respond along the lines of “I’m sorry Dave, but as a large language model I can’t let you do that,” otherwise you can just start feeding it text and seeing how it responds.
That having been said, prompt engineers have identified some basic constituent parts that go into useful prompts. They’re worth understanding as you go about using prompt engineering to build your brand voice.
Context
First, it helps to offer the LLM some context for the task you want done. Under most circumstances, it’s enough to give it a sentence or two, though there can be instances in which it makes sense to give it a whole paragraph.
Here’s an example prompt without good context:
“Can you write me a title for a blog post?”
Most human beings wouldn’t be able to do a whole lot with this, and neither can an LLM. Here’s an example prompt with better context:
“I’ve just finished a blog post for a client that makes legal software. It’s about how they have the best payments integrations, and the tone is punchy, irreverent, and fun. Could you write me a title for the post that has the same tone?”
To get exactly what you’re looking for you may need to tinker a bit with this prompt, but you’ll have much better chances with the additional context.
Instructions
Of course, the heart of the matter is the actual instructions you give the LLM. Here’s the context-added prompt from the previous section, whose instructions are just okay:
“I’ve just finished a blog post for a client that makes legal software. It’s about how they have the best payments integrations, and the tone is punchy, irreverent, and fun. Could you write me a title for the post that has the same tone?”
A better way to format the instructions is to ask for several alternatives to choose from:
“I’ve just finished a blog post for a client that makes legal software. It’s about how they have the best payments integrations, and the tone is punchy, irreverent, and fun. Could you give me 2-3 titles for the blog post that have the same tone?”
Here again, it’ll often pay to go through a couple of iterations. You might find – as we did when we tested this prompt – that GPT-4 is just a little too irreverent (it used profanity in one of its titles.) If you feel like this doesn’t strike the right tone for your brand identity you can fix it by asking the LLM to be a bit more serious, or rework the titles to remove the profanity, etc.
You may have noticed that “keep iterating and testing” is a common theme here.
Example Data
Though you won’t always need to get the LLM input data, it is sometimes required (as when you need it to summarize or critique an argument) and is often helpful (as when you give it a few examples of titles you like.)
Here’s the reworked prompt from above, with input data:
“I’ve just finished a blog post for a client that makes legal software. It’s about how they have the best payments integrations, and the tone is punchy, irreverent, and fun. Could you give me 2-3 titles for the blog post that have the same tone?
Here’s a list of two titles that strike the right tone:
When software goes hard: dominating the legal payments game.
Put the ‘prudence’ back in ‘jurisprudence’ by streamlining your payment collections.”
Remember, LLMs are highly sensitive to what you give them as input, and they’ll key off your tone and style. Showing them what you want dramatically boosts the chances that you’ll be able to quickly get what you need.
Output Indicators
An output indicator is essentially any concrete metric you use to specify how you want the output to be structured. Our existing prompt already has one, and we’ve added another (both are bolded):
“I’ve just finished a blog post for a client that makes legal software. It’s about how they have the best payments integrations, and the tone is punchy, irreverent, and fun. Could you give me 2-3 titles for the blog post that have the same tone? Each title should be approximately 60 characters long.
Here’s a list of two titles that strike the right tone:
When software goes hard: dominating the legal payments game.
Put the ‘prudence’ back in ‘jurisprudence’ by streamlining your payment collections.”
As you go about playing with LLMs and perfecting the use of prompt engineering in building your brand voice, you’ll notice that the models don’t always follow these instructions. Sometimes you’ll ask for a five-sentence paragraph that actually contains eight sentences, or you’ll ask for 10 post ideas and get back 12.
We’re not aware of any general way of getting an LLM to consistently, strictly follow instructions. Still, if you include good instructions, clear output indicators, and examples, you’ll probably get close enough that only a little further tinkering is required.
What Are The Different Types of Prompts You Can Use For Prompt Engineering?
Though prompt engineering for tasks like brand voice and tone building is still in its infancy, there are nevertheless a few broad types of prompts that are worth knowing.
- Zero-shot prompting: A zero-shot prompt is one in which you simply ask directly for what you want without providing any examples. It’ll simply generate an output on the basis of its internal weights and prior training, and, surprisingly, this is often more than sufficient.
- One-shot prompting: With a one-shot prompt, you’re asking the LLM for output and giving it a single example to learn from.
- Few-shot prompting: Few-shot prompts involve a least a few examples of expected output, as in the two titles we provided our prompt when we asked it for blog post titles.
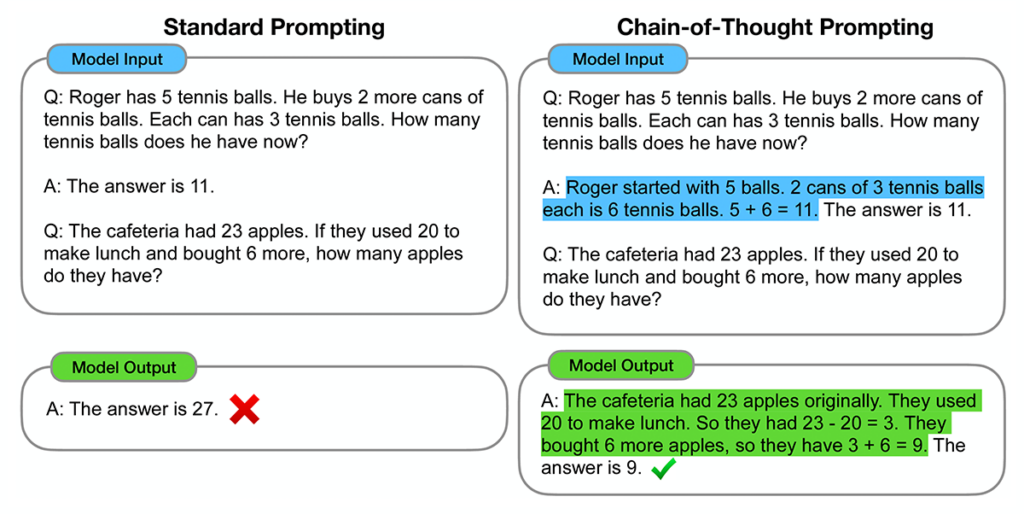
- Chain-of-thought prompting: Chain-of-thought prompting is similar to few-shot prompting, but with a twist. Rather than merely giving the model examples of what you want to see, you craft your examples such that they demonstrate a process of explicit reasoning. When done correctly, the model will actually walk through the process it uses to reason about a task. Not only does this make its output more interpretable, but it can also boost accuracy in domains at which LLMs are notoriously bad, like addition.
What Are The Challenges With Prompt Engineering For Brand Voice?
We don’t use the word “dazzling” lightly around here, but that’s the best way of describing the power of ChatGPT and the broader ecosystem of large language models.
You would be hard-pressed to find many people who have spent time with one and come away unmoved.
Still, challenges remain, especially when it comes to using prompt engineering for content marketing or building your brand voice.
One well-known problem is the tendency of LLMs to completely make things up, a phenomenon referred to as “hallucination”. The internet is now filled with examples of ChatGPT completely fabricating URLs, books, papers, professions, and individuals. If you use an LLM to create content for your website and don’t thoroughly vet it, you run the risk of damaging your reputation and your brand if it contains false or misleading information.
A related problem is legal or compliance issues that emerge as a result of using an LLM. Though the technology hasn’t been around long enough to get anyone into serious trouble (we suspect it won’t be long), there are now cases in which attorneys have been caught using faulty research generated by ChatGPT or engineering teams have leaked proprietary secrets by feeding meeting notes into it.
Finally, if you’re offering a fine-tuned model to customers to do something like answer questions, you must be very, very careful in delimiting its scope so that it doesn’t generate unwanted behavior. It’s pretty easy to accidentally wander into fraught territory when engaging with an LLM in an open-ended manner, and that’s not even counting users who deliberately try to get it to respond inappropriately.
One potential solution to this problem is by crafting your prompts such that they contain clear instructions about what not to do. You may tell it not to discuss its own rules, not to change its tone, not to speak negatively about anyone, not to argue, etc.
Crafting a prompt that illustrates the correct behavior while explicitly ruling out any incorrect behaviors is a non-trivial task, requiring a great deal of testing and refinement. But it’s one you’ll have to get right if you want to leverage LLMs for your brand voice while avoiding any possible harm down the line.
Prompt Engineering For Marketers
With all this context having been established, you’re no doubt excited about using prompt engineering in your marketing efforts. In this section, we’ll go through a couple of ways you can do that.
Coming up with ideas
One place where LLMs excel is in helping you with ideation. A lot goes into content marketing, but all of that follows from having a solid list of basic concepts to work from.
We tested ChatGPT’s functionality by feeding it this query:
“I’m starting a blog about becoming a data scientist. Could you give me a list of 10 blog post ideas, with a mix of beginner, intermediate, and advanced topics? The titles should be eye-catching but not too aggressive.
Here are two examples of good blog post titles:
‘Data science: what to know when considering a career in this hot new field.’
‘Data science v.s. data engineering: everything you wanted to know’”
And we got back some excellent ideas:
- “Demystifying Data Science: A Beginner’s Guide to Jumpstarting Your Career”
- “From Novice to Ninja: Essential Skills for Every Data Science Aspirant”
- “Unlocking the Power of Python: A Data Scientist’s Best Friend”
- “Exploratory Data Analysis: Unveiling Insights Hidden in the Numbers”
- “Machine Learning 101: A Gentle Introduction for Data Science Enthusiasts”
- “Feature Engineering: Enhancing Your Models Like a Pro”
- “The Art of Natural Language Processing: Extracting Meaning from Text”
- “Unsupervised Learning: Unveiling Patterns and Structure in Your Data”
- “Deep Dive into Neural Networks: Building Advanced Models for Predictive Analytics”
- “Data Science in the Real World: Tackling Complex Business Problems with Analytics”
And look, it even generated the correct number of titles! You’ll notice, though that every single one follows the same template, with an initial phrase, a colon, and then a follow-on phrase. That’s because the two examples I gave have this structure, and that’s what it used as a guide.
Performing Background Research
After you’re done coming up with good ideas for building your brand voice, you’ll likely want to do some additional background research on your domain. This, too, is a place where LLMs excel.
There can be a lot of subtlety to this. You might start with something obvious, like “give me a list of the top authors in the keto diet niche”, but you can also get more creative than this. We’ve heard of copywriters who have used GPT-3.5 to generate lengthy customer testimonials for fictional products, or diary entries for i.e. 40-year-old suburban dads who are into DIY home improvement projects.
Regardless, with a little bit of ingenuity, you can generate a tremendous amount of valuable research that can inform your attempts to develop a brand voice.
Be careful, though; this is one place where model hallucinations could be really problematic. Be sure to manually check a model’s outputs before using them for anything critical.
Generating Actual Content
Of course, one place where content marketers are using LLMs more often is in actually writing full-fledged content. We’re of the opinion that GPT-3.5 is still not at the level of a skilled human writer, but it’s excellent for creating outlines, generating email blasts, and writing relatively boilerplate introductions and conclusions.
Getting better at prompt engineering
Despite the word “engineering” in its title, prompt engineering remains as much an art as it is a science. Hopefully, the tips we’ve provided here will help you structure your prompts in a way that gets you good results, but there’s no substitute for practicing the way you interact with LLMs.
One way to approach this task is by paying careful attention to the ways in which small word choices impact the kinds of output generated. You could begin developing an intuitive feel for the relationship between input text and output text by simply starting multiple sessions with ChatGPT and trying out slight variations of prompts. If you really want to be scientific about it, copy everything over into a spreadsheet and look for patterns. Over time, you’ll become more and more precise in your instructions, just as an experienced teacher or manager does.
Prompt Engineering Can Help You Build Your Brand
Advanced AI models like ChatGPT are changing the way SEO, content marketing, and brand strategy are being done. From creating buyer personas to using chatbots for customer interactions, these tools can help you get far more work done with less effort.
But you have to be cautious, as LLMs are known to hallucinate information, change their tone, and otherwise behave inappropriately.
With the right prompt engineering expertise, these downsides can be ameliorated, and you’ll be on your way to building a strong brand. If you’re interested in other ways AI tools can take your business to the next level, schedule a demo of Quiq’s conversational CX platform today!
Contact Us