Key takeaways:
- LLM integrations turn static products into interactive systems by connecting large language models to real workflows and business data
- The real value comes from context, not just the model, retrieval and clean data are what make responses accurate and useful
- Without guardrails and clear prompt design, LLM outputs can become inconsistent or unreliable in production
- A successful integration depends on the full system, backend logic, frontend experience, and data flow all matter
- Most issues come from poor planning, unclear use cases and weak success metrics lead to wasted effort
- Real-world testing is critical, user inputs are messy and expose problems that demos never show
- LLM integrations require ongoing work, continuous monitoring and iteration are what drive long-term performance
Large language models have revolutionized just about every aspect of how we work and think in the past few years, and it seems like every business out there wants to add AI to their platforms. But does it make sense to add an LLM integration to your SaaS tool, website, or business model?
Today, we show you what an LLM integration is, the pros and cons of adding AI models to your current setup, and a full guide on how to make those integrations go live.
What is an LLM integration, and how does it work?
An LLM integration is the process of connecting large language models to your existing systems so they can read, reason, and respond using your business data. Instead of treating an LLM like a standalone chatbot, you plug it into your product, support stack, CRM, or internal tools and let it operate inside real workflows.
At a basic level, it works through API requests. You send a request to an API endpoint provided by the model vendor, authenticate it with an API key, and include the input you want the model to process. That input could be a customer message, a support ticket, or structured data from your backend. The model returns a response, which your application then displays or uses to trigger an action.
That’s the simple version. In practice, most useful implementations go a step further with retrieval augmented generation. Instead of relying only on what the model already knows, your system fetches relevant data, like help center articles, past conversations, or account details, and includes it in the request. The model then generates a response grounded in that context, which makes answers more accurate and business-specific.
Here’s how it typically plays out in a real workflow:
- A user asks a question in your app or support channel
- Your system pulls relevant data from internal sources
- You send everything to the model via an API request
- The model generates a response using that context
- The response is returned through the API endpoint and shown to the user
This is why LLM integration is so powerful: you are turning your existing data and systems into something that can interact, assist, and act in real time.
The benefits of adding an LLM integration to your product or service
Adding an LLM integration changes how your product communicates, supports users, and delivers value.
More natural communication
Most products still rely on predefined responses, rigid flows, or static content. That can create friction, especially when users ask something slightly outside the expected path.
With LLMs, you can generate human-like language that adapts to each situation. The tone can match your brand. The level of detail can be adjusted based on the question. Instead of forcing users through menus or forms, your product can respond directly.
This matters most in support, onboarding, and search experiences. Users get answers faster, and they do not feel like they are talking to a script.
Better control over outputs
There is a misconception that LLMs are unpredictable. In reality, you can guide them quite precisely.
You define the desired format for responses depending on the use case. For example, you can return short answers for chat, structured bullet summaries for internal tools, or step-by-step instructions for onboarding flows.
This level of control is especially useful in web apps where consistency matters. You are shaping how information is presented across your product.
Works with your existing stack
One of the biggest advantages is how easy LLMs are to integrate from a technical perspective.
They rely on API interactions, which means you can connect them to your product using almost any modern stack. Most teams already work with programming languages like JavaScript or Python, so adding LLM capabilities does not require a complete rebuild.
You send a request, include the necessary context, and receive a response. From there, you decide how that response is used, whether it is shown to a user, stored, or used to trigger another action.
Responses that reflect your business
Out of the box, LLMs are general-purpose, which is not enough for real products.
When you connect them to your own data, you unlock tailored responses that reflect your business logic, content, and users. That could include pulling in account details, referencing internal documentation, or using past interactions to shape the answer.
This is where the experience improves significantly: users are now getting answers that feel relevant and accurate.
New product capabilities without heavy rebuilds
Once you have the integration in place, you can start building new features on top of it without major engineering effort.
Common examples include:
- intelligent search that understands intent instead of keywords
- automated support that can handle a large portion of incoming questions
- in product assistants that guide users through complex workflows
- internal tools that help teams find information and complete tasks faster
The key point is that you are not replacing your product. You are extending it. And because everything runs through API interactions, you can keep iterating without slowing down your team.
The downsides of integrating LLMs
LLM integrations can unlock a lot of value, but they are not plug-and-play. Once you move beyond simple demos, a few consistent challenges show up. If you ignore them, you end up with unreliable features or frustrated users.
Unpredictable outputs
LLMs work with natural language, not fixed logic. That makes them flexible, but also harder to control.
The same input can produce slightly different answers. Small changes in user inputs can lead to completely different outputs. For simple use cases, this is manageable. For anything customer-facing or tied to business logic, it can become a problem.
You need guardrails. That includes validation layers, response checks, and clear boundaries on what the model is allowed to do.
Working with unstructured data
Most business data is not clean or standardized. It lives in documents, conversations, tickets, and notes.
LLMs can process unstructured data, but that does not mean they automatically understand it correctly. If your data is messy, outdated, or inconsistent, the output will reflect that.
To get reliable results, you need to organize and filter what you send to the model. That often means adding retrieval augmented generation layers, cleaning your data sources, and deciding what should or should not be included in each request.
Prompt engineering is not optional
Getting useful results from an LLM is not just about calling LLM APIs. How you structure the request matters just as much as the model itself.
Prompt engineering becomes a core part of the system. You need to define instructions, format inputs, and guide the model toward the right type of response.
This takes iteration. What works in testing may not hold up in production, especially when real users start sending unpredictable inputs.
Handling complex tasks is harder than it looks
LLMs are great at generating text, summarizing content, and answering questions. They are less reliable when tasks require strict logic, multiple steps, or exact accuracy.
When you try to use them for complex tasks, things can break down. The model may skip steps, misinterpret context, or produce confident but incorrect answers.
The solution is usually to combine LLMs with traditional logic. Let the model handle language, while your system handles rules, workflows, and validation.
Risk around sensitive data
Sending data to LLM APIs introduces real concerns around privacy and security.
If you are dealing with sensitive data, you need to be very clear about what is being sent, where it is processed, and how it is stored. That includes customer information, internal documents, and anything tied to compliance requirements.
In many cases, you will need to filter or redact data before making a request. You may also need stricter controls around access and logging.
Inconsistent model performance
Even with the right setup, the model’s performance can vary.
Changes in user inputs, updates from the provider, or shifts in your data can all impact results. What works well today may degrade over time if you are not monitoring it.
That is why ongoing evaluation matters. You need to track outputs, test edge cases, and continuously refine how your system interacts with the model.
LLMs are powerful, but they are not deterministic systems. Treating them like one is where most integrations fail.
10-point checklist: should you integrate an LLM into your product?
Before you jump into building, it is worth stepping back and pressure testing the idea. LLM integrations can unlock real value, but only if they fit your product, your data, and your users. Use this checklist to quickly sanity check whether it makes sense for you right now.
1. Do you have a real use case, not just curiosity?
Are you solving a clear problem, like improving support, search, or onboarding? If the idea is vague, the implementation will be too.
2. Will natural language actually improve the experience?
Does your product benefit from users typing or asking questions freely? If structured inputs already work well, you may not need it.
3. Do you have access to useful data?
LLMs are far more valuable when connected to your own data. Think knowledge bases, tickets, CRM data, or product usage history.
4. Is your data in a usable state?
If most of your data is messy or scattered across tools, you will struggle. Unstructured data can work, but it still needs some level of organization.
5. Can you define the desired output clearly?
Do you know what a “good” response looks like? Without a clear desired format, results will feel inconsistent.
6. Are you ready to handle unpredictable user inputs?
Users will ask unexpected questions and phrase things in strange ways. Your system needs guardrails to handle that safely.
7. Do you have the resources to iterate on prompt engineering?
This is not a one-time setup. You will need to refine prompts, test outputs, and improve over time.
8. Are you comfortable working with LLM APIs?
Your team should be able to handle API interactions, manage keys, and handle failures.
If not, expect a learning curve.
9. Have you thought about sensitive data?
Will you be sending customer or internal data through the system? If yes, you need a plan for filtering, compliance, and security.
10. Do you have a way to measure the model’s performance?
You need feedback loops. That could be user ratings, internal reviews, or tracking success rates on specific tasks.
If you are answering “yes” to most of these, you are in a strong position to move forward. If not, it is better to tighten the fundamentals first before adding another layer of complexity.
How to create an LLM integration, step by step
Wondering if you need conversational agents or some other shape or form of LLM integration? Here’s how you can get started, step by step.
1. Define the exact use case and success criteria
Before writing a single line of code, you need to get very clear on what you are actually building. This is where most LLM integrations fail. Teams jump straight into software development without defining the problem, and end up with something impressive but not useful.
Start with a specific use case.
Not “add AI to our product,” but something concrete like improving support response times, helping users find information faster, or assisting agents with replies. The narrower the scope, the easier it is to build something that works.
Then define what success looks like. That could be:
- reducing response time
- increasing resolution rates
- lowering support volume.
Without this, you will have no way to evaluate whether the integration is doing its job.
You also need to consider constraints early. Think about computational resources, expected usage, and how often the model will be called. A feature that looks simple on paper can become expensive or slow if you do not plan for scale.
Finally, align the use case with your existing workflows. Where will this live? Who will use it? What triggers it? If you cannot answer these questions clearly, the rest of the integration will feel disconnected from your product.
Get this step right, and everything that follows becomes much easier.
2. Choose the right model and provider
Once your use case is clear, the next step is picking the right model and provider. This decision has a direct impact on LLM performance, cost, and how reliable your integration will be in real use.
Start by matching the model to the task.
Not every use case needs the most advanced GPT model. Simpler tasks like summarization or classification can run well on lighter models, while more complex workflows need stronger reasoning and better context handling. Picking something too powerful can quickly increase costs, while picking something too limited will hurt output quality.
You also need to think about how this will feel for users.
If you are building AI assistants that interact in real time, response speed matters just as much as accuracy. Users expect quick replies, and even small delays can make the experience feel clunky. In many cases, a faster model with slightly lower capability is the better choice.
Next, consider your LLM usage. How often will the model be called, and under what conditions? Will it handle occasional requests or run on every user action? You also need to think about traffic spikes and whether your provider can handle them without performance issues. These factors will shape both cost and scalability.
Finally, look at the provider as a whole. Some platforms make it easier to manage API access, monitor usage, and scale over time. Others focus more on flexibility or pricing. The goal is not to pick the most advanced option available, but the one that fits your product and how you plan to use it.
3. Decide where the integration will live in your product
This is where things start getting real.
You already know what you want to build. Now you need to figure out where it actually fits. And this is a decision that affects adoption, performance, and whether the feature gets used at all.
Start by looking at your existing product flows.
Where are users getting stuck? Where do they need help, context, or faster answers? That is usually where an LLM integration makes the most sense.
For example, dropping it into a support chat is the obvious move. But sometimes the better play is less visible, like embedding it into a search bar, a dashboard, or even behind the scenes to assist your team instead of your users.
You also need to think about how it gets triggered. Is it always on, reacting to every user input, or does it activate in specific moments? If you overuse it, the product can feel noisy or unpredictable. If you hide it too much, people will not even realize it is there.
Another thing people underestimate is context. Wherever you place the integration, it needs access to the right data at the right moment. A support assistant inside a ticket view should see conversation history. A product assistant inside your app should understand what the user is doing right now.
The goal here is to place it where it naturally improves the experience, without forcing users to change how they already use your product.
4. Map the data sources the model needs to access
At this point, the integration starts to depend less on the model and more on your data.
LLMs are only as useful as the input data you give them. If you send vague or incomplete context, you will get vague answers back. If you send the right information, the model’s outputs become far more accurate and relevant.
Start by identifying what the model actually needs to do its job. For a support assistant, that might include help center articles, past conversations, and customer account details. For an internal tool, it could be documentation, reports, or product data.
Then look at where that data lives.
It is usually spread across multiple systems, your CRM, knowledge base, databases, or even third-party tools. You do not need to connect everything, but you do need to be intentional about what gets included.
Quality matters just as much as access.
If your data is outdated, duplicated, or inconsistent, the model will reflect that. This is where many integrations quietly break down. The model is fine, but the data feeding it is not.
You also need to think about how that data is retrieved. In most cases, you will not send everything at once. Instead, you pull only the most relevant pieces based on the situation, then include them in the request.
The goal here is simple. Make sure the model sees the right context at the right time. That is what turns generic responses into something genuinely useful.
5. Set up API access, authentication, and permissions
Now you are getting into the actual connection between your product and the model.
Large language models are typically accessed through APIs, so the first step is setting up secure access. This usually means generating an API key from your provider and making sure it is stored safely on your backend, never exposed in client-side code.
From there, you define how your system will communicate with the model. Every request needs to include the right input data, instructions, and any additional context you want the model to use. This is what shapes the model’s behavior and enables tailored responses instead of generic ones.
You also need to think about permissions early. Not every part of your system should have the same level of access. For example, an internal tool might be allowed to generate detailed summaries or assist with code generation, while a customer-facing feature should be more controlled and limited.
Data privacy is a big part of this step.
Before sending anything to the model, decide what data is safe to include and what needs to be filtered out. That could mean removing sensitive fields, anonymizing user data, or restricting certain types of requests entirely.
Finally, plan for failure cases. API calls can time out, fail, or return unexpected results. Your system should handle that gracefully, whether that means retrying the request, falling back to a default response, or prompting the user to try again.
This step is less about building features and more about building a reliable foundation. If the connection is not secure and stable, everything built on top of it will be shaky.
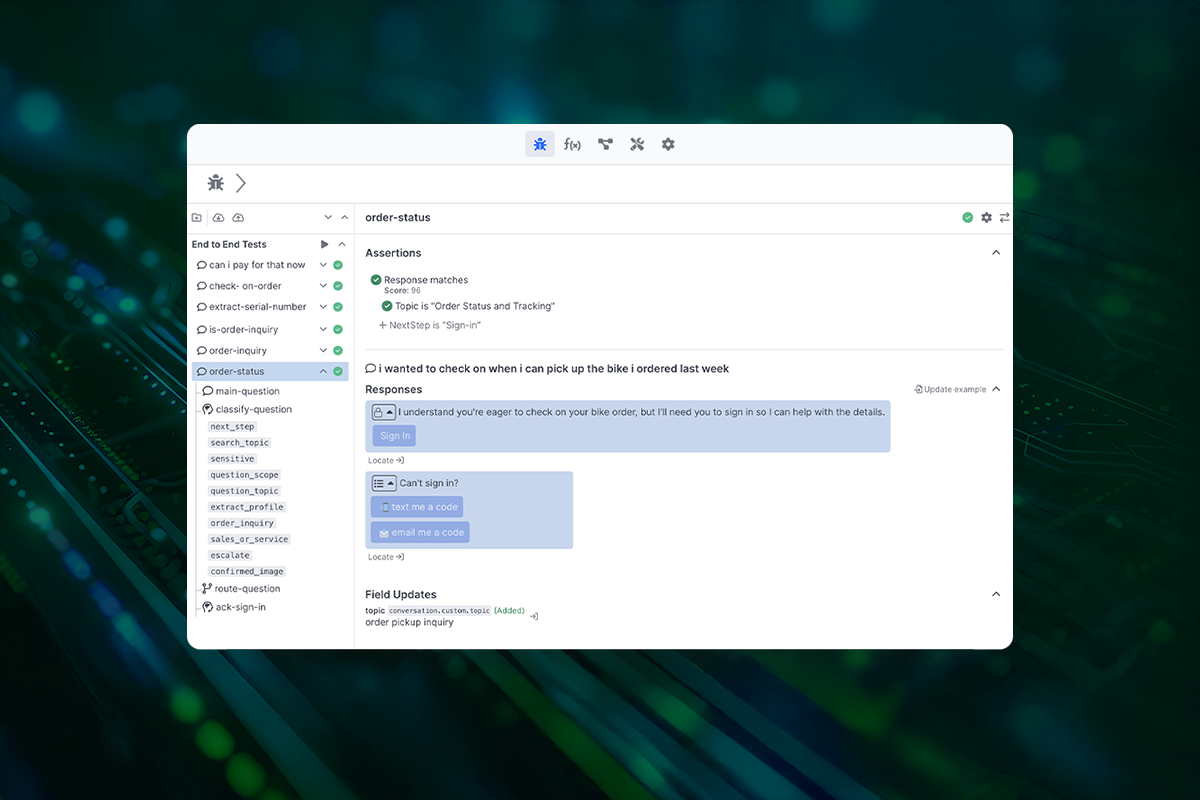
6. Design the prompt structure and response rules
This is the part that decides whether your integration feels sharp or sloppy.
A lot of teams assume the model will “figure it out” if they send enough text data and a loosely written instruction. Sometimes that works in a demo. In a real product, it usually does not. If you want reliable answers, you need to be deliberate about how each request is structured.
Start with the basics. What should the model do, what context should it use, and what should the answer look like? Those instructions need to be clear, consistent, and tied to the use case. If the model is helping with support, tell it how to answer, what sources to prioritize, and what it should avoid saying. If it is summarizing previous interactions, define what matters most, like key actions, unresolved issues, or customer sentiment.
You also need response rules.
Should the model answer only from approved sources? Should it say “I don’t know” when the context is weak? Should it keep answers short, or explain them in more detail? These decisions shape the experience more than most people expect.
This is also where error handling starts to matter. If the input is incomplete, contradictory, or missing context, your system should know what happens next. Maybe the model asks a follow-up question. Maybe it falls back to a safer default. Maybe it hands things off to a human.
A well-designed prompt structure will not magically solve everything, but it does give you consistency. And consistency is what turns an LLM feature from a novelty into a real competitive edge.
7. Add retrieval and context handling for smarter responses
Up to this point, you have a working connection and a structured prompt. Now comes the step that actually makes the experience feel useful instead of generic.
If you rely only on the model’s built-in knowledge, responses will sound decent but lack depth. They will not reflect your product, your users, or your data. To fix that, you need to bring in context at the moment the request is made.
This usually means pulling in relevant text data based on the situation. That could be help articles, account details, or previous interactions with the user. Instead of sending everything, you select only what matters and include it in the request.
This is how you move from generic replies to something that feels grounded and accurate. It is also what enables more interactive experiences. The model is reacting to what is happening in real time.
You should also think about flexibility here. Different LLMs handle context in slightly different ways. Some perform better with shorter, focused inputs, while others can manage larger chunks of information. Your setup should allow you to adjust how context is passed in without rewriting everything.
When this is done well, the difference is obvious. Instead of producing surface-level answers, the model can generate human-like text that actually reflects the user’s situation. That is what makes the integration feel like a real feature, not just an add-on.
8. Build the backend logic for requests, responses, and fallbacks
This is where everything starts to come together behind the scenes.
At a basic level, your backend is responsible for deciding when to send prompts, what goes into them, and what happens with the response. But in practice, it does a lot more than that. It becomes the control layer between your product and the model.
Start by defining how requests are triggered. That could be a user action, a system event, or part of a workflow. Once triggered, your backend gathers the right context, builds the prompt, and sends it to the model. The response then needs to be processed before it is returned to the user or used elsewhere in your system.
This is also where you introduce structure. For example, you might route different types of requests to different AI agents, each responsible for a specific task like answering questions, summarizing content, or handling internal queries. This helps keep things organized, especially as your integration grows.
You also need to think about scale. What works for a small feature can break under large scale usage. That means handling retries, managing timeouts, and making sure your system does not fail when the model is slow or unavailable.
Fallbacks are critical here. If the model cannot produce a reliable answer, your system should know what to do next. That could mean returning a default response, asking for clarification, or handing things off to a human.
Finally, keep in mind that large language models rely on general knowledge unless you guide them otherwise. If you need more specialized behavior, you may explore fine-tuning or additional layers of control, but even then, your backend logic is what keeps everything predictable and usable.
9. Create the frontend experience for user inputs and outputs
Now it is time to think about what users actually see and interact with.
You can have a powerful backend, but if the frontend experience is clunky, people will not use it. The goal here is to make interactions feel simple, even when the system behind them is handling complex problems.
Start with how users provide input. This could be a chat interface, a search bar, or a structured form. Keep it intuitive. Users should not need instructions to understand how to interact. In many cases, a simple text field is enough, especially when you want them to ask questions in their own words.
On the output side, clarity matters more than anything. The response should be easy to read and match the context of your product. Sometimes that means plain text. Other times, it means structured responses in a JSON format that your UI can render into tables, lists, or action steps.
You also need to handle feedback loops. Give users a way to react to responses, whether that is thumbs up, corrections, or follow-up questions. This helps you improve the system over time.
From a technical perspective, keep sensitive details out of the frontend. Things like your API key should always stay on the backend, typically stored in an ENV file. The frontend should only communicate with your own services, not directly with the model provider.
If you are integrating with tools like Power Automate or other workflow systems, make sure the experience stays consistent. The user should not feel like they are jumping between disconnected tools.
A clean frontend turns your LLM integration from a technical feature into something people actually rely on.
10. Add guardrails for security, accuracy, and sensitive data handling
This is the step that separates a clever demo from something you can trust in a real product.
LLMs can produce useful answers, but they can also get things wrong, overstate confidence, or respond in ways that do not fit your policies. That is why guardrails matter. You need clear limits around what the model can see, what it can say, and what it is allowed to do.
Start with data controls. Decide what information can be passed into the model and what should never leave your system in raw form. Customer records, payment details, private messages, and internal documents all need careful handling. In some cases, you may need to redact fields before the request is sent. In others, you may block certain data entirely.
Then focus on output control. The model should not be free to answer anything in any way. You can set rules for tone, length, approved sources, and restricted topics. You can also require the system to decline when confidence is low instead of guessing.
Validation matters too. If the model returns a response that triggers an action, like updating a record or sending a message, that output should be checked before anything happens. Let the model handle language, but keep sensitive decisions behind rules and verification.
It is also smart to log responses, flag risky cases, and review failures regularly. Not because the system is broken, but because real users will always find edge cases you did not plan for.
This part is not glamorous, but it is one of the most important steps in the entire integration. Without guardrails, even a good model becomes hard to trust.
11. Test with real scenarios, edge cases, and messy inputs
This is where you find out if your integration actually works.
Testing LLM features is very different from testing traditional software. You are not just checking if something runs without errors. You are evaluating the quality, consistency, and usefulness of LLM outputs across a wide range of situations.
Start with realistic scenarios. Use actual customer support conversations, real user queries, and typical workflows from your product. Synthetic examples are useful early on, but they rarely reflect how people behave in practice.
Then push beyond the obvious cases. What happens when users are vague, frustrated, or unclear? What if they provide incomplete information or mix multiple questions into one? These edge cases are where large models tend to struggle, and where poor experiences show up.
You should also test how the system behaves under different conditions. Try switching prompts, adjusting context, or even comparing responses across different configurations from your LLM provider. Small changes can have a big impact on output quality.
Another important area is failure handling. What happens when the model does not know the answer, or returns something incorrect? Does your system catch it, or does it pass straight through to the user?
Finally, involve real people in testing. Internal teams, especially those in customer support, are great at spotting issues quickly because they know what good answers should look like.
The goal here is not perfection. It is confidence that your system can handle real-world usage without breaking or frustrating users.
12. Measure performance, iterate, and improve over time
Launching the integration is not the finish line. It is the starting point.
LLMs are not static systems.
The quality of the LLM’s response can change based on user behavior, data quality, and even updates from your provider. If you are not actively measuring performance, things can quietly degrade without you noticing.
Start by defining what success looks like in practice. That could be resolution rates in customer support, accuracy of answers, user satisfaction, or how often the system completes specific tasks without human intervention. Pick a few metrics that actually reflect value, not just usage.
Then track how the system performs in real conditions. Look at where it succeeds, but pay even more attention to where it struggles. Are there patterns in failures? Are certain types of questions consistently producing weak answers? That is where your biggest improvements will come from.
User feedback is especially valuable here. If people correct the system, ask follow-up questions, or abandon the interaction, those signals tell you something is off.
From there, you iterate. You adjust prompts, refine how context is passed in, improve data quality, and tweak how your system handles edge cases. Sometimes small changes can lead to much more optimal results.
Over time, this is how your integration becomes reliable. It learns from real usage, adapts to new scenarios, and gets better at helping users perform tasks without friction.
The teams that treat LLM integrations as evolving systems, not one-time features, are the ones that see long-term impact.
Why Quiq is the smarter choice for CX focused LLM integrations
Most LLM integrations look good in a demo. Clean prompts, perfect inputs, ideal conditions. Then real customers show up, and things start to break.
Questions are messy. Context is missing. Conversations jump between topics. And suddenly, your “AI feature” is either giving vague answers or making things up with confidence.
That is exactly where Quiq fits in.
Quiq is not trying to be a general-purpose AI layer for any app. It is built specifically for customer experience, where the stakes are higher, and the margin for error is smaller. Every interaction needs to be accurate, consistent, and grounded in a real business context.
Instead of just passing prompts to a model, Quiq focuses on orchestration. It connects large language models with your data, your workflows, and your support systems in a way that actually holds up in production. That means better handling of context, cleaner handoffs between automation and human agents, and responses that reflect what is actually happening with the customer.
It also gives you more control where it matters. You can shape how conversations are handled, how data is used, and when the system should step back instead of guessing. That is critical in customer support, where a wrong answer is worse than no answer.
If your goal is to build something flashy, you have plenty of options. If your goal is to deliver consistent customer experiences at scale, Quiq is built for that.
And that is the difference that shows up when real users start interacting with your system.Book a demo with Quiq to see how we can improve your customer experience with AI.