Customer experience directors tend to have a lot of questions about AI, especially as it becomes more and more important to the way modern contact centers function.
These can range from “Will generative AI’s well-known tendency to hallucinate eventually hurt my brand?” to “How are large language models trained in the first place?” along with many others.
Speaking of training, one question that’s often top of mind for prospective users of Quiq’s conversational AI platform is whether we train the LLMs we use with your data. This is a perfectly reasonable question, especially given famous examples of LLMs exposing proprietary data, such as happened at Samsung. Needless to say, if you have sensitive customer information, you absolutely don’t want it getting leaked – and if you’re not clear on what is going on with an LLM, you might not have the confidence you need to use one in your contact center.
The purpose of this piece is to assure you that no, we do not train LLMs with your data. To hammer that point home, we’ll briefly cover how models are trained, then discuss the two ways that Quiq optimizes model behavior: prompt engineering and retrieval augmented generation.
How are Large Language Models Trained?
Part of the confusion stems from the fact that the term ‘training’ means different things to different people. Let’s start by clarifying what this term means, but don’t worry–we’ll go very light on technical details!
First, generative language models work with tokens, which are units of language such as a part of a word (“kitch”), a whole word (“kitchen”), or sometimes small clusters of words (“kitchen sink”). When a model is trained, it’s learning to predict the token that’s most likely to follow a string of prior tokens.
Once a model has seen a great deal of text, for example, it learns that “Mary had a little ____” probably ends with the token “lamb” rather than the token “lightbulb.”
Crucially, this process involves changing the model’s internal weights, i.e. its internal structure. Quiq has various ways of optimizing a model to perform in settings such as contact centers (discussed in the next section), but we do not change any model’s weights.
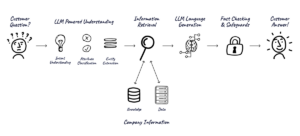
How Does Quiq Optimize Model Behavior?
There are a few basic ways to influence a model’s output. The two used by Quiq are prompt engineering and retrieval augmented generation (RAG), neither of which does anything whatsoever to modify a model’s weights or its structure.
In the next two sections, we’ll briefly cover each so that you have a bit more context on what’s going on under the hood.
Prompt Engineering
Prompt engineering involves changing how you format the query you feed the model to elicit a slightly different response. Rather than saying, “Write me some social media copy,” for example, you might also include an example outline you want the model to follow.
Quiq uses an approach to prompt engineering called “atomic prompting,” wherein the process of generating an answer to a question is broken down into multiple subtasks. This ensures you’re instructing a Large Language Model in a smaller context with specific, relevant task information, which can help the model perform better.
This is not the same thing as training. If you were to train or fine-tune a model on company-specific data, then the model’s internal structure would change to represent that data, and it might inadvertently reveal it in a future reply. However, including the data in a prompt doesn’t carry that risk because prompt engineering doesn’t change a model’s weights.
Retrieval Augmented Generation (RAG)
RAG refers to giving a language model an information source – such as a database or the Internet – that it can use to improve its output. It has emerged as the most popular technique to control the information the model needs to know when generating answers.
As before, that is not the same thing as training because it does not change the model’s weights.
RAG doesn’t modify the underlying model, but if you connect it to sensitive information and then ask it a question, it may very well reveal something sensitive. RAG is very powerful, but you need to use it with caution. Your AI development platform should provide ways to securely connect to APIs that can help authenticate and retrieve account information, thus allowing you to provide customers with personalized responses.
This is why you still need to think about security when using RAG. Whatever tools or information sources you give your model must meet the strictest security standards and be certified, as appropriate.
Quiq is one such platform, built from the ground-up with data security (encryption in transit) and compliance (SOC 2 certified) in mind. We never store or use data without permission, and we’ve crafted our tools so it’s as easy as possible to utilize RAG on just the information stores you want to plug a model into. Being a security-first company, this extends to our utilization of Large Language Models and agreements with AI providers like Microsoft Open AI.
Wrapping Up on How Quiq Trains LLMs
Hopefully, you now have a much clearer picture of what Quiq does to ensure the models we use are as performant and useful as possible. With them, you can make your customers happier, improve your agents’ performance, and reduce turnover at your contact center.