Key Takeaways
- Generative AI is the broadest category. It refers to any AI system capable of creating new content (text, images, audio, code), based on patterns learned from data.
- LLMs (Large Language Models) are a subset of generative AI. Their specialization is in human-language tasks (writing, summarizing, dialogue). They understand and generate text but don’t inherently take autonomous actions.
- Agentic AI adds autonomy and agency. Beyond just generating outputs, agentic AI can plan, make decisions, execute tasks, adapt strategy, and act with minimal human input.
- These AI types can complement each other in workflows. For example: generative AI might create content, an LLM might refine its tone or structure, and an agentic system could autonomously schedule, send, analyze feedback, and iterate.
The release of tools like ChatGPT sparked a wave of excitement and confusion around AI. Suddenly, terms like “generative AI,” “large language models,” and now “agentic AI” are being used interchangeably in headlines, product pitches, and boardrooms.
But while they’re all related, they’re not the same.
Generative AI is the broadest term, describing any AI system that creates something new, whether it’s text, images, audio, or code. Large language models (LLMs) are a specific kind of generative AI focused on language tasks like writing, summarizing, and answering questions.
And agentic AI? That’s where things get even more interesting. Agentic AI builds on the capabilities of generative AI and LLMs, but adds autonomy, taking action, making decisions, and executing tasks with minimal human input.
In this article, we’ll break down the differences between these three types of AI, explore how they work together, and explain why the future of customer experience lies in going beyond just generating responses to actually getting things done.
What Is Generative AI?
Of the three terms, “generative AI” is broader, referring to any machine learning model capable of dynamically creating output after it has been trained.
This ability to generate complex forms of output, like sonnets or code, is what distinguishes generative AI from other types of machine learning.
Besides being much simpler, these models can only “generate” output in the sense that they can make a prediction on a new data point.
There are many key features of generative AI, so let’s spend some time discussing how it can be used and the benefits it can provide.
Key Features of Generative AI
Generative AI is designed to create new content, learning from vast datasets to produce text, images, audio, and video. Its capabilities extend beyond simple data processing, making it a powerful tool for creativity, automation, and personalization.
Content Generation
At its core, Generative AI excels at producing unique and original content across multiple formats, including text, images, audio, and video. Unlike traditional AI systems that rely on predefined rules, generative models leverage deep learning to generate coherent and contextually relevant outputs. This creative capability has revolutionized industries ranging from marketing to entertainment.
Data-Driven Learning
Generative AI models are trained on vast datasets, allowing them to learn complex patterns and relationships within the data. These models use deep neural networks, particularly transformer-based architectures, to process and generate information in a way that mimics human cognition. By continuously analyzing new data, generative AI can refine its outputs and improve over time, making it increasingly reliable for content generation, automation, and decision-making.
Adaptability & Versatility
One of the most powerful aspects of Generative AI is its ability to function across diverse industries and use cases. Whether it’s generating realistic human-like conversations in chatbots, composing music, or designing virtual environments, the technology adapts seamlessly to different applications. Its versatility allows businesses to leverage AI-driven creativity without being limited to a single domain.
Customization & Personalization
Generative AI can tailor its outputs based on user inputs, preferences, or specific guidelines. This makes it an invaluable tool for personalized content creation, such as crafting targeted marketing messages, customizing chatbot responses, or even generating personalized artwork. By adjusting parameters or fine-tuning models with proprietary data, businesses can ensure that the AI-generated content aligns with their brand voice and audience expectations.
Effeciency & Automation
Beyond creativity, Generative AI significantly enhances efficiency by automating tasks that traditionally require human effort. Whether it’s generating reports, summarizing large volumes of text, or producing high-quality design assets, AI-driven automation saves time and resources. This efficiency allows businesses to scale their operations while reducing costs and freeing up human talent for higher-level strategic work.
What Are Large Language Models?
Now that we’ve covered generative AI, let’s turn our attention to large language models (LLMs).
LLMs are a particular type of generative AI.
Unlike with MusicLM or DALL-E, LLMs are trained on textual data and then used to output new text, whether that be a sales email or an ongoing dialogue with a customer.
(A technical note: though people are mostly using GPT-4 for text generation, it is an example of a “multimodal” LLM because it has also been trained on images. According to OpenAI’s documentation, image input functionality is currently being tested, and is expected to roll out to the broader public soon.)
Key Features of Large Language Models
LLMs represent a breakthrough in AI-powered language processing, offering unparalleled natural language capabilities, scalability, and adaptability. Their ability to understand and generate text with contextual awareness makes them invaluable across industries. Below, we explore the key features that make LLMs so powerful and their significance in real-world applications.
Natural Language Understanding & Generation
One of the defining characteristics of LLMs is their ability to comprehend and generate human language with contextually relevant and coherent output. Unlike traditional rule-based NLP systems, LLMs leverage deep learning to process vast amounts of text, enabling them to recognize nuances, idioms, and contextual dependencies.
Why this matters: This enables more natural interactions in chatbots, virtual assistants, and customer support tools. It also improves content generation for marketing, reporting, and creative writing, while multilingual capabilities enhance accessibility and global communication.
Scalability & Versatility:
LLMs are designed to process and generate text at an unprecedented scale, making them versatile across a wide range of applications. They can analyze large datasets, respond to queries in real-time, and generate text in multiple formats—from technical documentation to creative storytelling.
Why this matters: Their scalability allows businesses to automate tasks, improve decision-making, and generate personalized content efficiently. This versatility makes them useful across industries like healthcare, finance, and education, streamlining operations and enhancing user engagement.
Adaptability Through Fine-Tuning
While general-purpose LLMs are highly capable, their performance can be further enhanced through fine-tuning—a process that tailors the model to specific domains or tasks. By training an LLM on industry-specific data, organizations can improve accuracy, reduce bias, and align responses with their unique needs.
Why this matters: Fine-tuning increases accuracy for specialized tasks, ensuring better performance in industries like healthcare and law. It also helps businesses maintain brand consistency and reduces the need for manual corrections, leading to more efficient workflows.
What Are Examples of Large Language Models?
By far the most well-known example of an LLM is OpenAI’s “GPT” series, the latest of which is GPT-4. The acronym “GPT” stands for “Generative Pre-Trained Transformer”, and it hints at many underlying details about the model.
GPT models are based on the transformer architecture, for example, and they are pre-trained on a huge corpus of textual data taken predominately from the internet.
GPT, however, is not the only example of an LLM.
The BigScience Large Open-science Open-access Multilingual Language Model – known more commonly by its mercifully short nickname, “BLOOM” – was built by more than 1,000 AI researchers as an open-source alternative to GPT.
BLOOM is capable of generating text in almost 50 natural languages, and more than a dozen programming languages. Being open-sourced means that its code is freely available, and no doubt there will be many who experiment with it in the future.
In March, Google announced Bard, a generative language model built atop its Language Model for Dialogue Applications (LaMDA) transformer technology.
As with ChatGPT, Bard is able to work across a wide variety of different domains, offering help with planning baby showers, explaining scientific concepts to children, or helping you make lunch based on what you already have in your fridge
What is Agentic AI?
Agentic AI refers to artificial intelligence systems that go beyond passive data processing to actively pursue objectives with minimal human intervention. Unlike traditional AI models that rely on explicit prompts or predefined workflows, agentic AI autonomously takes initiative, gathers information, and makes decisions in pursuit of a goal.
At its core, agentic AI operates with a level of autonomy that allows it to dynamically adapt to new information, refine its approach, and execute tasks with greater independence. These systems can analyze complex scenarios, break down multi-step problems, and determine the best course of action without requiring constant human oversight.
Advancements in AI, from reinforcement learning to multi-agent collaboration, have enabled agentic AI to evolve from passive tools into autonomous problem-solvers. Businesses now use it to streamline workflows, enhance decision-making, and drive efficiency, signaling a shift toward proactive AI systems.
What are some of the key features of Agentic AI?
As stated before, Agentic AI represents a significant evolution beyond traditional AI models, offering enhanced autonomy and decision-making capabilities. Let’s discuss some of Agentic AI’s key features:
Autonomous Action
One of the defining characteristics of Agentic AI is its ability to operate without constant human intervention. Rather than waiting for step-by-step instructions, it executes tasks independently, identifying the necessary actions to reach an objective. This autonomy allows it to function in dynamic environments, where manual oversight would be inefficient or impractical.
Dynamic Decision Making
Agentic AI leverages real-time data to continuously refine its decision-making process. It evaluates multiple factors, adapts to changing conditions, and optimizes its approach based on the latest available information. This ability to course-correct and adjust strategies in real-time makes it particularly effective for complex problem-solving and unpredictable scenarios.
Goal-Oriented Behavior
Unlike conventional AI models that react to prompts, Agentic AI operates with a clear end goal in mind. It identifies obstacles, prioritizes tasks, and makes trade-offs to achieve its objectives efficiently. Whether optimizing workflows, automating multi-step processes, or navigating constraints, it maintains a results-driven approach.
Proactive Resource Gathering
To function effectively, Agentic AI does not simply wait for relevant data or tools to be provided—it actively seeks out the necessary resources. This can include retrieving information from databases, leveraging APIs, integrating with other systems, or even initiating sub-tasks to support the primary goal. This proactive approach enhances efficiency and reduces dependency on human input.
Self-Improvement Through Feedback
Agentic AI continuously refines its performance through iterative learning. By analyzing the outcomes of past actions, it identifies areas for improvement and adjusts future behaviors accordingly. This feedback loop allows it to become more effective over time, reducing errors and increasing efficiency in completing assigned tasks.
What Are Some Examples of Agentic AI?
Now that we have explained what Agentic AI is and some of its key features, you may be wondering how businesses in various industries are using Agentic AI. Here are a few examples:
1. Personalized AI Assistants: Beyond Basic Task Execution
AI assistants have come a long way from setting reminders and answering basic questions. Today’s agentic AI assistants can handle entire workflows, making life a whole lot easier.
Imagine having an AI-powered executive assistant that not only manages your calendar but also rearranges meetings when scheduling conflicts pop up, prioritizes your emails, and even drafts responses for you. In sales, AI agents integrated into CRMs can track conversations, spot promising leads, and automatically schedule follow-ups—no manual input required.
2. AI in Healthcare: Keeping an Eye on Your Health
Healthcare is another area where agentic AI is making a real difference. Instead of passively analyzing data, these AI systems can continuously monitor patient health, detect problems early, and even adjust treatment plans on the fly.
For example, some AI-powered health monitoring tools track vital signs in real-time, alerting doctors if something seems off. Others can analyze medical records and suggest personalized treatments based on a patient’s history. In some cases, AI can even adjust medication dosages automatically, ensuring patients get the right treatment without constant doctor intervention.
3. AI That Actually Solves Customer Support Issues
We’ve all had frustrating experiences with chatbots that don’t understand what we’re asking. Agentic AI is fixing that by powering virtual support agents that don’t just respond to questions—they solve problems.
Picture this: You need to return an item, and instead of navigating through endless menus, an AI agent processes your return, updates your order, and even schedules a pickup without you lifting a finger. In IT support, AI-powered agents can troubleshoot issues, restart systems, and even execute fixes automatically. No more waiting on hold for help—AI’s got it covered.
How Do Agentic AI, Generative AI, and LLM’s Compare?
Artificial intelligence has rapidly evolved, with distinct categories emerging to define different capabilities and use cases. While Generative AI, Large Language Models (LLMs), and Agentic AI share foundational principles, they each serve unique purposes.
Key Differences Between Generative AI, LLMs, and Agentic AI
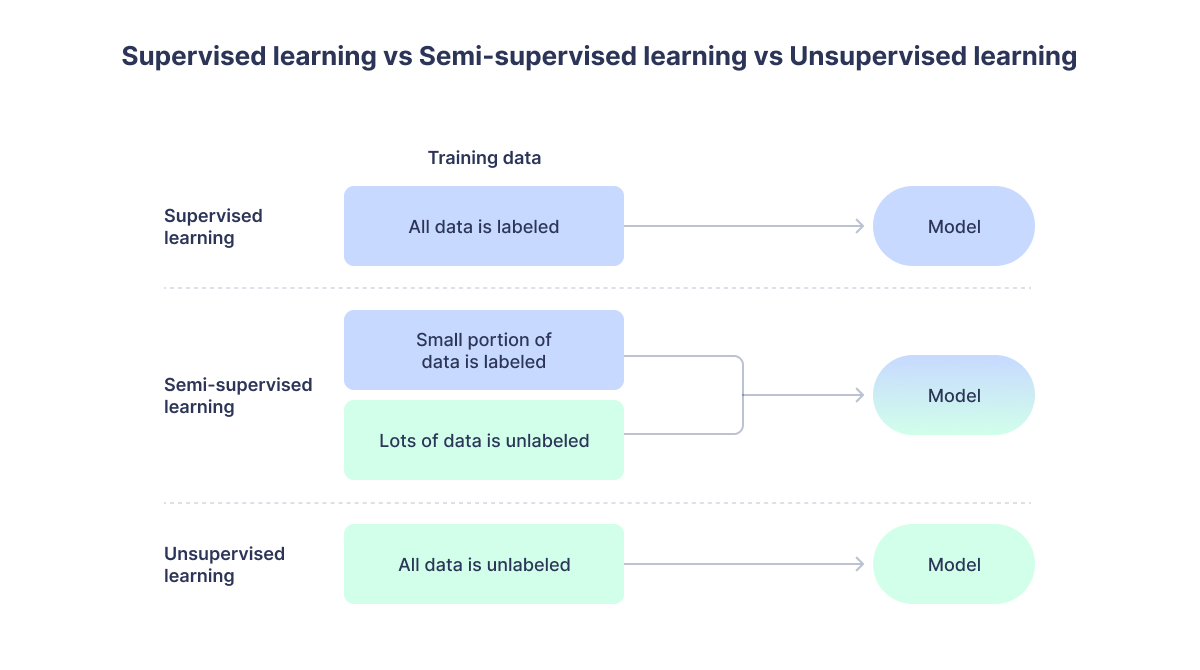
- Generative AI: This is the broad umbrella term for AI models that create content, whether text, images, music, or video. These models generate outputs based on patterns learned from large datasets but typically require user input to function effectively.
- Large Language Models: A subset of Generative AI, LLMs specialize in language-based tasks such as text generation, summarization, translation, and answering questions. They process vast amounts of textual data to produce human-like responses but do not inherently make decisions or take autonomous action.
- Agentic AI: Unlike Generative AI and LLMs, Agentic AI goes a step further by incorporating autonomy and goal-driven behavior. It not only generates outputs but also plans, executes, and adapts actions based on objectives. This makes Agentic AI well-suited for tasks that require decision-making, iterative problem-solving, and multi-step execution.
How These AI Systems Can Work Together
Agentic AI, Generative AI, and LLMs are not mutually exclusive; rather, they complement each other in complex workflows. For example:
- A Generative AI model might generate a marketing email.
- An LLM could refine the email’s tone and structure based on customer preferences.
- An Agentic AI system could autonomously schedule and send the email, analyze customer responses, and iterate on the next campaign.
This synergy enables businesses and organizations to streamline operations, automate complex workflows, and improve decision-making at scale.
When to Use Generative AI, LLMs, or Agentic AI
As AI continues to evolve, different types of AI serve distinct roles in automation, content creation, and decision-making. Choosing the right approach—Generative AI, Large Language Models (LLMs), or Agentic AI—depends on the complexity of the task, the level of autonomy required, and the desired outcome. Here’s when to use each.
Examples of when to Use Generative AI
Generative AI is best suited for tasks that involve creativity, personalization, and idea generation. It excels at producing original content and enhancing user engagement by tailoring outputs dynamically.
- For Creative Content Generation: Generative AI shines when creating unique visuals, music, text, or videos. It’s widely used in industries like marketing, design, and entertainment.
- For Prototyping and Idea Generation: When brainstorming ideas or rapidly iterating on design concepts, generative AI can provide inspiration and streamline workflows.
- For Enhancing Personalization: Generative AI helps tailor content for individual users, making it a powerful tool in marketing, product recommendations, and customer engagement.
Examples of when to Use Large Language Models (LLMs)
LLMs specialize in processing and generating human-like text, making them ideal for knowledge work, communication, and conversational AI.
- For Text-Based Tasks: LLMs handle content creation, summarization, translation, and text analysis with high efficiency.
- For Conversational AI: They power chatbots, virtual assistants, and customer support tools by enabling natural, context-aware conversations.
- For Knowledge Work and Research: LLMs assist in research, code generation, and complex problem-solving, making them valuable for technical fields.
Examples of when to Use Agentic AI
Agentic AI goes beyond content generation and text processing—it autonomously executes tasks, makes decisions, and manages workflows with minimal human input.
- For Automating Multi-Step Tasks: Agentic AI can plan, make decisions, and execute complex workflows without constant human oversight.
- For Goal-Oriented, CX-Focused Systems: In scenarios where AI needs to take action toward a specific objective, agentic AI ensures execution beyond just responding to queries.
- For Enhancing Productivity in Complex Workflows: When managing multiple tools or systems, agentic AI improves efficiency by handling strategic yet repetitive tasks.
Utilizing Generative AI In Your Business
AI is evolving fast, but not all AI is created equal. Generative AI is great for creativity, LLMs handle text-based tasks, but agentic AI is the game-changer—turning AI from an assistant into an autonomous problem-solver. That’s where Quiq stands out. Instead of just generating responses, Quiq’s agentic AI takes action, automating complex tasks and making real decisions so businesses can scale without the bottlenecks. It’s AI that doesn’t just assist—it gets things done.
Quiq is the leader in enterprise agentic AI for CX. If you’re an enterprise wondering how you can use advanced AI technologies such as agentic AI, generative AI, and large language models for applications like customer service, schedule a demo to see what the Quiq platform can offer you!
Key Takeaways
Generative AI is a broad category of AI that creates new content—text, images, audio, and more—based on patterns learned from data.
Large Language Models (LLMs) are a specific type of generative AI designed to understand and generate human-like text. Popular examples include GPT-4 and Google Bard.
Agentic AI goes beyond generating content. It acts autonomously toward goals, making decisions, gathering resources, and completing tasks without constant human input.
While generative AI and LLMs focus on content creation, agentic AI introduces action and execution, enabling more complex, goal-driven workflows.
Together, these AI types can be combined to power smarter, more efficient systems—from content creation to fully automated customer experiences.
Quiq’s platform is built on agentic AI, helping enterprises move beyond chat to real, scalable automation that drives outcomes.
Frequently Asked Questions (FAQs)
What is Generative AI?
Generative AI refers to any AI system that can create new content – like text, images, or code- by learning from patterns in large datasets. It powers tools that write, draw, or compose in ways that mimic human creativity.
How do Large Language Models (LLMs) fit into Generative AI?
LLMs are a subset of generative AI designed to understand and produce human language. They’re the engines behind AI agents, content generation, summarization, and translation tools.
What is Agentic AI?
Agentic AI builds on the foundation of generative and language models by adding autonomy. These systems don’t just generate content; they can make decisions, plan actions, and execute tasks independently to achieve goals with minimal human input.
What makes Agentic AI different from LLMs?
While LLMs focus on understanding and producing text, Agentic AI combines reasoning, memory, and tools to act on that information – bridging the gap between “thinking” and “doing.”
Are LLMs and Agentic AI competing technologies?
Not at all. In fact, they complement each other. LLMs handle natural language understanding and generation, while Agentic AI leverages these capabilities to take real actions and deliver tangible outcomes.
Why does Agentic AI matter for CX?
Agentic AI moves beyond scripted chatbots; it enables real problem-solving at scale, helping businesses automate workflows, personalize experiences, and deliver faster resolutions.