
Key Takeaways
- Semi-supervised learning combines a small set of labeled data with a large set of unlabeled data to improve model performance.
- Common methods include self-training (model teaches itself with pseudo-labels), co-training (two models teach each other), and graph-based learning (labels spread through data connections).
- It’s useful when labeling data is expensive or time-consuming, like in fraud detection, content classification, or image analysis.
- Semi-supervised learning is different from self-supervised learning (predicting parts of data) and active learning (asking for labels on uncertain data).
From movie recommendations to AI agents as customer service reps, it seems like machine learning (ML) is everywhere. But one thing you may not realize is just how much data is required to train these advanced systems, and how much time and energy goes into formatting that data appropriately.
Machine learning engineers have developed many ways of trying to cut down on this bottleneck, and one of the techniques that has emerged from these efforts is semi-supervised learning.
Today, we’re going to discuss semi-supervised learning, how it works, and where it’s being applied.
What is Semi-Supervised Learning?
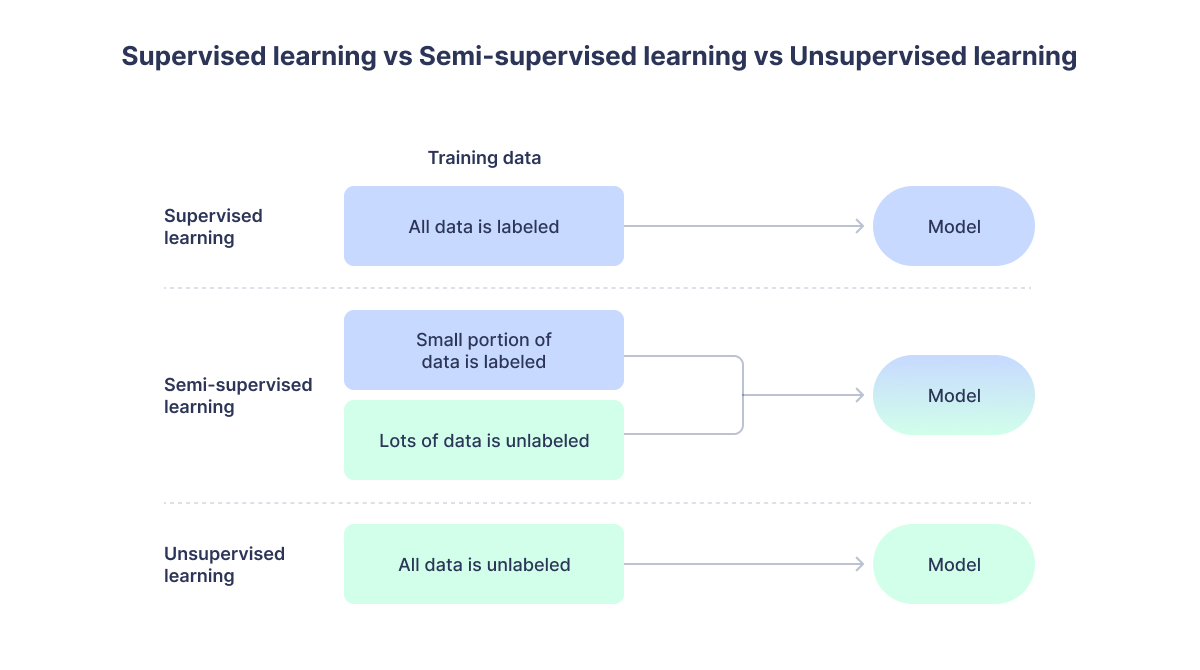
Semi-supervised learning (SSL) is an approach to machine learning (ML) that is appropriate for tasks where you have a large amount of data that you want to learn from, only a fraction of which is labeled.
Semi-supervised learning sits somewhere between supervised and unsupervised learning, and we’ll start by understanding these techniques because that will make it easier to grasp how semi-supervised learning works.
- Supervised learning: refers to any ML setup in which a model learns from labeled data. It’s called “supervised” because the model is effectively being trained by showing it many examples of the right answer.
- Unsupervised learning: requires no such labeled data. Instead, an unsupervised machine learning algorithm is able to ingest data, analyze its underlying structure, and categorize data points according to this learned structure.
Like we stated previously, semi-supervised learning combines elements of supervised and unsupervised learning. Instead of relying solely on labeled data (like supervised models) or unlabeled data (like unsupervised ones), it uses a small labeled dataset alongside a larger unlabeled one to improve accuracy and efficiency.
This approach is especially useful when labeling data is costly or time-consuming, such as tagging support chats or images. The labeled examples guide the model’s understanding, while the unlabeled data helps it generalize to new patterns. By blending both data types, semi-supervised learning strikes a balance between performance and scalability, making it ideal for AI applications like intent detection, chat automation, and content moderation.
How Does Semi-Supervised Learning Work?
The three main variants of semi-supervised learning are self-training, co-training, and graph-based label propagation, and we’ll discuss each of these in turn.
Self-training
Self-training is the simplest kind of semi-supervised learning, and it works like this.
A small subset of your data will have labels while the rest won’t have any, so you’ll begin by using supervised learning to train a model on the labeled data. With this model, you’ll go over the unlabeled data to generate pseudo-labels, so-called because they are machine-generated and not human-generated.
Now, you have a new dataset; a fraction of it has human-generated labels while the rest contains machine-generated pseudo-labels, but all the data points now have some kind of label, and a model can be trained on them.
Co-training
Co-training has the same basic flavor as self-training, but it has more moving parts. With co-training, you’re going to train two models on the labeled data, each on a different set of features (in literature, these are called “views”).
If we’re still working on that plant classifier from before, one model might be trained on the number of leaves or petals, while another might be trained on their color.
At any rate, now you have a pair of models trained on different views of the labeled data. These models will then generate pseudo-labels for all the unlabeled datasets. When one of the models is very confident in its pseudo-label (i.e., when the probability it assigns to its prediction is very high), that pseudo-label will be used to update the prediction of the other model, and vice versa.
Let’s say both models come to an image of a rose. The first model thinks it’s a rose with 95% probability, while the other thinks it’s a tulip with a 68% probability. Since the first model seems really sure of itself, its label is used to change the label on the other model.
Think of it like studying a complex subject with a friend. Sometimes a given topic will make more sense to you, and you’ll have to explain it to your friend. Other times, they’ll have a better handle on it, and you’ll have to learn from them.
In the end, you’ll both have made each other stronger, and you’ll get more done together than you would’ve done alone. Co-training attempts to utilize the same basic dynamic with ML models.
Graph-based semi-supervised learning
Another way to apply labels to unlabeled data is by utilizing a graph data structure. A graph is a set of nodes (in graph theory, we call them “vertices”) which are linked together through “edges.” The cities on a map would be vertices, and the highways linking them would be edges.
If you put your labeled and unlabeled data on a graph, you can propagate the labels throughout by counting the number of pathways from a given unlabeled node to the labeled nodes.
Imagine that we’ve got our fern and rose images in a graph, together with a bunch of other unlabeled plant images. We can choose one of those unlabeled nodes and count up how many ways we can reach all the “rose” nodes and all the “fern” nodes. If there are more paths to a rose node than a fern node, we classify the unlabeled node as a “rose”, and vice versa. This gives us a powerful alternative means by which to algorithmically generate labels for unlabeled data.
[button link=”https://quiq.com/contact-us/?utm_source=website&utm_medium=blog&utm_campaign=semi-super-learning&utm_content=button-cta”]Contact Us[/button]
Common Semi-Supervised Applications
The amount of data in the world is increasing at a staggering rate, while the number of human-hours available for labeling it all is increasing at a much less impressive clip. This presents a problem because there’s no end to the places where we want to apply machine learning.
Semi-supervised learning presents a possible solution to this dilemma, and in the next few sections, we’ll describe semi-supervised learning examples in real life.
- Identifying cases of fraud: In finance, semi-supervised learning can be used to train systems for identifying cases of fraud or extortion.
- Classifying content on the web: The internet is a big place, and new websites are put up all the time. In order to serve useful search results, it’s necessary to classify huge amounts of this web content, which can be done with semi-supervised learning.
- Analyzing audio and images: When audio files or image files are generated, they’re often not labeled, which makes it difficult to use them for machine learning. Beginning with a small subset of human-labeled data, however, this problem can be overcome with semi-supervised learning.
What Are the Benefits of Semi-Supervised Learning?
Semi-supervised learning delivers the best of both worlds – strong model performance without the steep cost of fully labeled datasets. Here are a few key benefits:
Key benefits include:
- Cost Efficiency: Reduces the need for extensive manual labeling, allowing teams to use mostly unlabeled data while still achieving high accuracy.
- Better Model Generalization: Improves a model’s ability to recognize patterns in new or unseen data by leveraging diverse, unlabeled examples.
- Enhanced Performance: Even with limited labeled data, semi-supervised models often outperform those trained solely with supervised techniques.
- Improved Data Utilization: Makes full use of available data resources, turning previously “unused” unlabeled data into valuable training material.
- Scalability: Easily adapts as new unlabeled data becomes available, allowing continuous improvement without repeating costly labeling cycles.
- Faster Deployment: Requires less upfront labeled data, meaning models can reach production readiness sooner and refine over time with additional feedback.
In essence, semi-supervised learning helps organizations maximize the value of their data – achieving stronger, more adaptable AI systems without the traditional bottlenecks of data labeling and cost.
When Should You Use Semi-Supervised Learning (and When Not To)
Semi-supervised learning is most effective when you have a large pool of unlabeled data but only a small amount of labeled data. It’s designed for situations where labeling is expensive or time-consuming, but unlabeled data is plentiful and easy to collect.
When to Use It
- Labeled Data is Scarce or Costly: Ideal when labeling requires specialized expertise or significant manual effort.
- Unlabeled Data is Abundant: Works well when you have vast quantities of raw data – like chat transcripts, audio clips, or product images.
- To Prevent Overfitting: Adding unlabeled data gives the model more context, helping it generalize better and avoid overfitting to a limited labeled set.
- For Unstructured Data: Especially effective for text, image, and audio datasets where manual labeling is challenging or subjective.
- When Supervised or Unsupervised Learning Falls Short: If supervised learning lacks enough labels for accuracy and unsupervised learning lacks direction, semi-supervised learning strikes the balance between structure and scale.
When to Not Use It
- When Labeled Data is Already Plentiful: If you have a lot of high-quality labeled data, fully supervised learning will usually yield better and more predictable results than semi-supervised learning.
- For Highly Regulated or Sensitive Applications: In domains like finance or healthcare compliance, the uncertainty of unlabeled data may pose additional risk unless carefully validated.
- When Data Quality Is Poor: If your unlabeled dataset contains errors, duplicates, or inconsistencies, the model can amplify those problems rather than learn from them.
In short: use semi-supervised learning when you have lots of data, little labeling capacity, and need to scale efficiently. Avoid it when your labeled data is already sufficient or your unlabeled data isn’t reliable enough to guide the model.
The Bottom Line
Semi-supervised learning empowers businesses to get more value out of the data they already have, without waiting for fully labeled datasets. By combining a small amount of labeled data with a much larger pool of unlabeled data, teams can build smarter, faster, and more adaptive models that continually improve over time.
That same principle powers Quiq’s Agentic AI – a solution designed to help enterprise teams leverage their own data to train intelligent, context-aware AI agents. With built-in automation and learning loops, Quiq’s platform helps businesses scale insights, personalize customer interactions, and accelerate innovation with no endless data labeling required.
If you’re exploring how to make your data work harder for you, it’s the perfect time to see what’s possible with Quiq’s AI Studio.
Frequently Asked Questions (FAQs)
What is semi-supervised learning in simple terms?
Semi-supervised learning is a machine learning approach that uses a small amount of labeled data and a large amount of unlabeled data to train models more efficiently.
How is semi-supervised learning different from supervised and unsupervised learning?
Supervised learning relies only on labeled data, while unsupervised learning uses none. Semi-supervised learning blends both, improving accuracy when labeling is costly or limited.
What are some real-world examples of semi-supervised learning?
It’s used in areas like fraud detection, medical image analysis, customer sentiment classification, and speech recognition – where gathering labeled data is time-consuming or expensive.
What are the main techniques in semi-supervised learning?
Common methods include self-training (the model generates pseudo-labels), co-training (multiple models teach one another), and graph-based algorithms (labels spread through data relationships).
Why is semi-supervised learning important?
It helps businesses and researchers make better use of large unlabeled datasets, reducing labeling costs while still achieving high model accuracy.
[button link=”https://quiq.com/demo/?utm_source=website&utm_medium=blog&utm_campaign=semi-super-learning&utm_content=bottom-cta”]Request A Demo[/button]


