Key takeaways
- Conversational AI in healthcare uses natural language processing to automate patient scheduling, symptom checking, and medication reminders while maintaining 24/7 availability without requiring human staff.
- Agentic AI systems maintain conversation context and execute tasks like appointment booking, while traditional healthcare chatbots follow rigid scripts and provide information only.
- Healthcare organizations typically see ROI within the first year through reduced call center volume, lower cost per patient contact, and improved staff efficiency by automating routine administrative tasks.
- HIPAA-compliant conversational AI platforms require end-to-end encryption, role-based access controls, and complete audit trails to handle protected health information in healthcare environments.
Healthcare organizations handle millions of patient interactions each year, and the math simply doesn’t work anymore. Staff can’t keep up with call volumes, patients wait too long for answers, and administrative tasks pull clinicians away from actual care.
Conversational AI offers a practical path forward by automating routine patient communication while keeping humans in the loop for complex situations. This guide covers how the technology works, where it delivers measurable results, and what to consider when evaluating platforms for your organization.
What is conversational AI in healthcare?
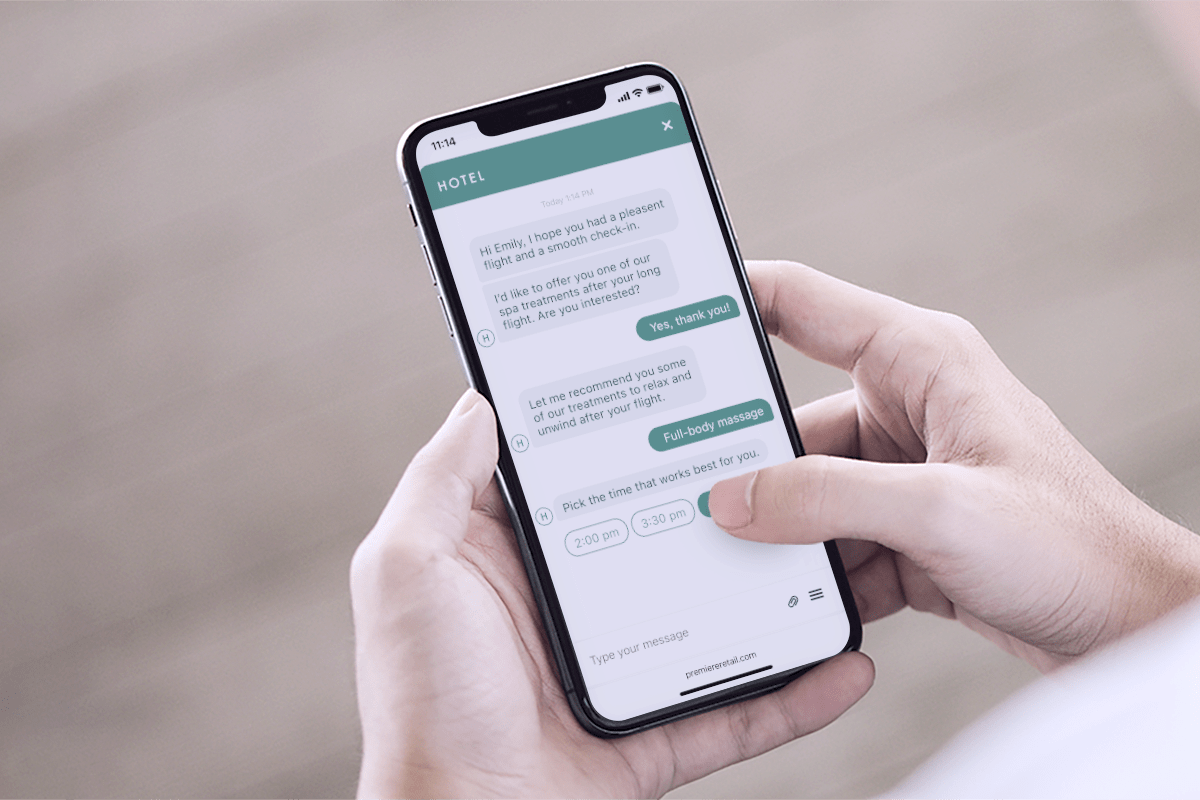
Conversational AI in healthcare uses natural language processing to simulate human conversation via voice or text, streamlining patient engagement and administrative tasks. The technology enables 24/7 patient scheduling, symptom checking, and medication reminders while helping clinicians with documentation through voice commands.
You’ve probably encountered automated phone trees that make you press 1, then 3, then 7, only to end up nowhere useful. Conversational AI is different. It actually understands what patients are asking, interprets intent, and responds in ways that feel like human-like interactions rather than navigating a maze.
The technology powers conversational AI chatbots, virtual assistants, and voice-enabled systems across health organizations. Patients can ask questions, book appointments, or report symptoms without waiting for a human to become available.
How conversational AI technology works in health systems

Natural language processing for patient communication
Natural language processing, or NLP, is the engine that allows AI to interpret patient questions regardless of phrasing.
A patient might ask “When can I see Dr. Smith?” while another types “I need to schedule a checkup.” NLP recognizes both as appointment requests and responds accordingly. Machine learning models continuously improve these interpretations over time, making the system more accurate with every patient conversation.
The technology works across voice and text channels. Patients can speak to a voice assistant or type into a chat window, and the AI processes both inputs the same way, understanding human language naturally.

Integration with electronic health records (EHR)
For conversational AI to provide personalized responses, it connects directly to electronic health records. When a patient asks about upcoming appointments or recent lab results, the AI pulls that information in real time from the EHR system, giving healthcare providers immediate access to relevant information.
The connection works both ways. The AI can also update patient records by logging appointment changes, capturing intake information, or noting symptoms a patient reports during a conversation.
Agentic AI assistants vs traditional healthcare chatbots for patient care
Traditional chatbots follow rigid scripts. If a patient’s question doesn’t match a predefined path, the conversation hits a dead end. Agentic AI works differently because it reasons through problems, maintains context across multiple exchanges, and takes actions on behalf of patients.
| Feature | Traditional Chatbots | Agentic AI |
|---|---|---|
| Conversation style | Scripted, menu-based | Dynamic, goal-oriented |
| Context retention | Limited or none | Maintains full conversation history |
| Problem-solving | Follows fixed paths | Reasons through complex scenarios |
| Actions | Provides information only | Can execute tasks like scheduling and updates |
The distinction matters because healthcare conversations rarely follow predictable paths. A patient asking about a prescription refill might also mention a new symptom, then ask about their next appointment. Agentic AI handles that natural flow while traditional chatbots struggle.
Benefits of conversational AI for healthcare organizations

24/7 patient engagement and support
Patients don’t get sick on a schedule.
When someone has a question at 2 AM about their medication or wants to reschedule an appointment over the weekend, conversational AI provides instant responses without requiring staff to be available.
Around-the-clock availability reduces after-hours call volume and gives patients continuous support and answers when they actually have questions, helping to improve patient access across the board.
Reduced administrative burden on clinical staff
Front desk staff often spend hours each day on repetitive tasks, like confirming appointments, answering the same insurance questions, and collecting intake information.
Conversational AI handles many of these routine administrative tasks automatically, which frees staff to focus on patients who are physically present and improving patient access to timely care.
Improved patient satisfaction and NPS scores
Faster responses lead to happier patients. When someone can book an appointment in two minutes via chat instead of waiting on hold for fifteen, their perception of the entire care experience improves.
Meeting patient expectations for speed and convenience is a significant driver of overall patient satisfaction.
Consistency matters too. AI delivers the same quality response, whether it’s the first call of the day or the five hundredth, driving measurable improvements in patient satisfaction metrics.
Operational efficiency and lower operational costs
Fewer manual touchpoints per patient interaction directly reduces cost per contact and improves operational efficiency across the organization.
Healthcare organizations typically see returns through reduced call center volume and improved staff efficiency, streamlining administrative workflows that previously consumed significant resources.
Faster response and resolution times
AI resolves common patient inquiries immediately. A patient checking their appointment time gets an answer in seconds, rather than waiting in a queue.
For more complex issues, the AI gathers relevant information before connecting patients to the right team member, so when a human does step in, they have context from the start.
Key applications of conversational AI for healthcare providers
Appointment management conversational AI
AI handles booking, rescheduling, and cancellations through natural conversation, automating appointment scheduling end to end. Patients state what they want, and the system finds available times, confirms details, and sends reminders via SMS or voice, effectively minimizing missed appointments.
Automated reminders alone can significantly reduce no-show rates, which directly impacts revenue and resource utilization for health systems.
Symptom checking and patient triage
When patients aren’t sure whether they require urgent care or can wait for a regular appointment, AI-guided patient triage helps. The system asks clarifying questions to assess urgency and routes patients appropriately.
AI triage supports clinical judgment rather than replacing it. The system identifies high-risk symptoms and alerts staff to emergencies while directing routine concerns to appropriate channels.
Patient intake and registration
Collecting demographics, insurance information, and medical history before visits reduces waiting room paperwork.
Patients complete patient intake through a conversational interface at their convenience, and the patient information flows directly into the EHR, reducing the need for an in-person visit just to complete paperwork.
Billing and insurance inquiries
Questions like “What’s my balance?” and “Do you accept my insurance?” consume significant staff time.
Conversational AI answers billing and coverage questions instantly by pulling from billing systems to provide accurate, personalized information.
Understanding health insurance portability and coverage details is something AI assistants can clearly explain to patients.
Prescription refills and medication reminders
Patients can request refills through a simple conversation. The AI verifies the prescription, checks with the pharmacy, and confirms when it’s ready.
Adherence reminders help patients stay on track with their medications, which is particularly valuable for chronic condition management and supporting self care between visits.
Post-visit follow-up and care coordination
After appointments, AI can check in with patients about their recovery, remind them of care instructions, and escalate concerns to care teams when warranted.
Ongoing engagement helps improve patient outcomes without adding to clinical workload. These touchpoints also support patient education by reinforcing treatment plans and helping to improve patient education between visits.
Mental health support
Conversational AI systems are increasingly used to provide mental health support by offering emotional support and helping walk patients through self care resources between clinical appointments.
AI assistants can provide continuous support for patients managing anxiety, depression, or other conditions, flagging concerns to healthcare professionals when escalation is needed.
While AI does not replace clinical care, it extends the reach of mental health services significantly.
Clinical decision support for healthcare professionals
Beyond patient-facing applications, conversational AI tools assist clinicians directly. Clinical decision support powered by artificial intelligence helps healthcare professionals surface relevant patient data, flag potential drug interactions, and suggest evidence-based next steps during care delivery.
Conversational artificial intelligence makes it possible for clinicians to query patient records using natural language, reducing the time spent navigating complex systems and allowing them to focus on patient care.
AI in healthcare is evolving rapidly, and conversational AI platforms are increasingly embedded in clinical workflows to assist clinicians rather than replace them. These conversational AI solutions give healthcare teams valuable data at the point of care, supporting better decisions and helping to improve patient outcomes across the healthcare sector.
HIPAA compliance and security healthcare data

Protected health information requirements
Any system handling patient data in healthcare falls under HIPAA regulations. Protected health information includes anything that could identify a patient, from names and dates to medical records and even IP addresses in some contexts.
Maintaining health insurance portability and accountability standards is non-negotiable for any conversational AI system deployed in the healthcare industry.
Conversational AI platforms designed for healthcare build compliance into their architecture from the ground up rather than adding it as an afterthought.
Security protocols and data encryption
Healthcare-grade security involves multiple layers of protection:
- End-to-end encryption. All patient conversations are protected in transit and at rest.
- Role-based access controls. Limits on who can view conversation logs and patient data.
- Secure authentication. Patient verification before accessing personal health information.
AI governance and audit trails
Visibility into AI decisions matters for compliance. When regulators or internal teams want to understand why the AI responded a certain way, they can trace the logic through decision trees and audit logs.
Transparency separates enterprise-ready platforms from consumer-grade tools. Full audit trails make compliance reviews straightforward rather than anxiety-inducing.
Challenges of implementing conversational AI for health systems
Integration with legacy healthcare systems
Many health systems run older EHRs and scheduling platforms that weren’t designed with AI integration in mind. Custom integration work is often required, and timelines vary based on system complexity.
Maintaining clinical accuracy
AI responses in healthcare carry real consequences. Conversational AI systems require ongoing training and oversight to provide medically appropriate information and recognize when to escalate to a human. Patient safety must remain the top priority throughout deployment and ongoing operation.
Staff adoption and change management
Clinical staff may initially resist new tools, particularly if previous technology implementations created more work rather than less. Successful rollouts require training and clear demonstration of value before expanding.
Patient trust and acceptance
Some patients prefer human interaction, especially for sensitive health matters. Well-designed AI makes escalation easy and handles opt-outs gracefully so patients never feel trapped in an automated loop.
How conversational AI supports healthcare teams without replacing them
A common concern is whether AI will take jobs from healthcare workers. The reality is more nuanced.
Conversational AI handles routine tasks so clinical staff can focus on complex, high-value patient interactions. When a nurse isn’t spending twenty minutes on the phone confirming appointments, they can spend that time with patients who require their expertise. Healthcare professionals remain essential to patient care, with AI technology as a force multiplier, not a substitute.
The AI collects information, answers common questions, and escalates to humans when the situation calls for it. It’s a tool that extends capacity, rather than a replacement for clinical judgment.
Answering frequently asked questions, for example, is an area where conversational AI tools deliver significant advantages by freeing healthcare teams for higher-complexity work.
Continuous support across the healthcare journey
Effective conversational AI solutions don’t just handle isolated interactions — they enhance patient engagement across the entire healthcare journey.
From the first inquiry through post-visit follow-up, AI virtual assistants provide continuous support that helps improve patient engagement at every stage. This ongoing presence helps healthcare providers build stronger relationships with patients, improve patient education, and ultimately enhance patient care delivery across the healthcare sector.
Conversational AI systems that maintain context throughout the patient experience allow healthcare organizations to deliver more consistent, personalized communication. The result is a patient experience that feels connected rather than fragmented, helping to enhance patient engagement and meet rising patient expectations.
How to evaluate conversational AI platforms for the healthcare industry
Essential features for healthcare use cases
- Omnichannel support. Voice, SMS, chat, and patient portal integration.
- HIPAA compliance. Built-in security and audit capabilities.
- EHR integration. Connects to your existing health records system.
- Escalation handling. Smooth handoff to human agents with full context.
- Transparency. Visibility into how AI makes decisions.
Questions to ask AI vendors
When evaluating platforms, consider asking vendors how they handle PHI and maintain HIPAA compliance, whether you can see how the AI reaches its conclusions, what integration with existing systems requires, how conversations transfer between AI and human agents, and what control you have over the AI’s responses and guardrails.
Integration and implementation considerations
Most healthcare organizations can launch initial conversational AI capabilities within weeks rather than months, though complex integrations take longer. Starting with a pilot program for appointment scheduling or FAQ handling allows teams to demonstrate value before expanding to additional use cases.

The future of AI healthcare conversational assistants
Voice-powered clinical documentation is already emerging, allowing clinicians to update EHRs hands-free during patient encounters.
Proactive outreach, where AI reaches out to patients before they reach out to you, is becoming more sophisticated.
Deeper personalization, multilingual support, and tighter integration across care settings will continue to evolve. Organizations investing in conversational AI infrastructure now are positioning themselves for what comes next in healthcare delivery.
Building connected patient experiences with conversational AI
The best conversational AI for healthcare maintains context across every patient touchpoint. A patient who starts a conversation via chat and continues it by phone doesn’t have to repeat themselves, because the system remembers the full history.
Connected patient experiences look like one continuous conversation across channels, with full visibility into how AI decisions are made, and easy escalation to humans when appropriate.
FAQs about conversational AI in healthcare
How do patients typically respond to AI-powered healthcare communication?
Patient acceptance depends heavily on the quality of the experience. AI that resolves inquiries quickly and offers easy access to human support generally receives positive reception. Transparency about when patients are interacting with AI also builds trust.
What happens when conversational AI cannot resolve a patient inquiry?
Well-designed healthcare conversational AI recognizes its limitations and escalates to human agents with full conversation context. Patients don’t have to repeat themselves, and agents have the information they require to help immediately.
Can healthcare conversational AI handle multiple languages for diverse patient populations?
Many platforms support multiple languages, though capabilities vary significantly. Evaluate language support based on your specific patient demographics and communication requirements before selecting a vendor.
What is the typical return on investment for conversational AI in health systems?
ROI depends on call volume and current staffing costs. Healthcare organizations typically see returns through reduced cost per contact, lower call volume, and improved staff efficiency, often within the first year of deployment.
How long does it take to implement conversational AI in a healthcare organization?
Implementation timelines vary based on integration complexity and use case scope. Most healthcare organizations can launch initial capabilities within weeks, though connecting to legacy systems or rolling out across multiple departments typically extends the timeline.