The CX Leaders’ Guide to Crush the Competition
As customer expectations continue to rise, businesses are under increasing pressure to provide fast, efficient, and personalized service around the clock. For CX leaders, keeping up with these demands can be challenging—especially when scaling operations while maintaining high-quality support. This is where a Voice AI platform can give you the edge you need to transform your customer service strategy.
Voice AI is a powerful technology that rapidly changes how businesses interact with their customers. From automating routine tasks to delivering personalized experiences at scale, Voice AI is truly changing the game in customer service.
This article explores how Voice AI works, why it’s more effective than traditional human agents in many areas, and the numerous benefits it offers businesses today. Whether you’re just beginning to explore Voice AI or looking to enhance your existing systems, this guide will provide valuable insights into how this technology can revolutionize your approach to customer service and help you stay ahead of the competition.
What is Voice AI and how does it work?
Voice AI refers to technology that uses artificial intelligence to understand, process, and respond to human speech. It enables machines to engage in natural, spoken conversations with users, typically using tools like automatic speech recognition (ASR), natural language processing (NLP), and text-to-speech (TTS) to convert spoken language into text, interpret intent, and generate verbal responses. Voice AI is commonly used in applications like virtual assistants, customer service, and AI agents.
A Voice AI platform is a comprehensive system that enables businesses to build, deploy, and manage voice-based interactions powered by artificial intelligence. It integrates all the technologies mentioned above into a single solution to provide tools to design conversational flows, customize voice AI agents, handle customer queries, and gather analytics to improve performance. Voice AI platforms are now being used to create virtual assistants, customer service, and contact centers to improve the customer experience and change the way customers interact with businesses.
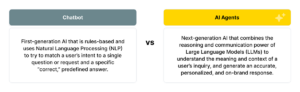
Voice AI enables machines to understand, interpret, and respond to human speech in a natural, conversational way. Unlike the early days of chatbots and voice systems, today’s Voice AI agents are powered by advanced technologies like Large Language Models (LLMs), such as GPT and many others, which allow them to comprehend and respond to human language with impressive accuracy.
LLMs are trained on massive amounts of data, allowing them to recognize patterns in speech, understand different languages and dialects, and predict what a user asks—even if the question is phrased unexpectedly. This is a major leap from traditional, rules-based systems, which required rigid, predefined scripts to function. Now, Voice AI agents can understand intent and context, making conversations feel much more natural and intuitive.
When a customer speaks to a Voice AI agent, the process begins with Automatic Speech Recognition (ASR), which converts spoken language into text. Once the words are captured, Natural Language Processing (NLP) kicks in to interpret the meaning behind the words, analyzing context and intent to determine the best response. From there, the system generates a response using the LLM’s understanding of language, and finally, the text is converted back into speech with Text-to-Speech (TTS) technology. All this happens in real time through a conversational voice AI platform, allowing the customer to interact with the AI as if they were speaking to a human agent.
For CX leaders, this changes everything for your customers. Voice AI agents don’t just hear words—they understand them. This allows you to handle a wide range of customer inquiries, from simple requests like checking order status to more complex tasks such as troubleshooting issues or answering product questions. And because these AI agents constantly learn from each interaction, they continue to improve over time, becoming more efficient and effective with each use.
How Voice AI compares to human agents
One of the most common questions CX leaders ask is how Voice AI compares to human agents. While it’s true that AI agents can’t fully replace the human touch in all interactions, they offer several key advantages that are transforming customer service for the better.
1. Consistency and speed
Unlike human agents, who may vary in their responses or make mistakes, Voice AI agents provide consistent answers every time—as long as they have appropriate guardrails in place to prevent hallucinations. Without these safeguards, AI can generate misinformation and fail to meet customer needs. Properly trained AI agents, equipped with the necessary guardrails, can instantly access vast amounts of information and handle inquiries quickly, making them ideal for routine or frequently asked questions. This ensures that customers receive fast, accurate responses without the need to wait on hold or navigate through multiple layers of human interaction.
2. 24/7 availability
One of the biggest benefits of Voice AI is that it’s available around the clock. Whether it’s the middle of the night or during peak business hours, AI agents are always on, ready to assist customers whenever they need help. This is especially useful for global businesses that operate in different time zones, ensuring customers can access support without delay, no matter where they are.
3. Scalability
Another advantage of Voice AI agents is their ability to scale. Unlike human agents, who can only handle one conversation at a time, AI agents can manage thousands of interactions simultaneously. This makes them particularly valuable during busy periods, such as holidays or product launches, when call volumes can surge. Instead of overwhelming your team, Voice AI ensures that all customers receive the same high level of service, even during high-demand times.
Where human agents excel
Of course, there are still areas where human agents outperform AI. Empathy and emotional intelligence are crucial in customer service, especially when dealing with complex or sensitive issues.
While AI agents can empathize with a user who expresses emotion, they are limited in their ability to interpret those emotions, and lack the personal touch that human agents excel at. Similarly, when faced with complex problem solving that requires out-of-the-box thinking, a human agent’s creativity and judgment are often more effective.
For these reasons, many businesses find that a hybrid approach works best—using Voice AI to handle routine or straightforward tasks, while allowing human agents to focus on more complex or emotionally charged interactions. This not only ensures that customers receive the right level of support, but also frees up human agents to do what they do best: solve problems and connect with customers on a personal level.
5 big business impacts of Voice AI
Now that we’ve covered how Voice AI works and compares to human agents, let’s review the specific benefits it offers businesses. From cost savings to enhanced customer experiences, Voice AI is transforming the way companies approach customer service.
1. Increased efficiency and reduced costs
One of the most significant advantages of using Voice AI is the ability to automate routine tasks. Instead of relying on human agents to handle simple inquiries—such as checking an order status, answering frequently asked questions, or processing payments—AI agents can manage these tasks automatically. This reduces the workload for human agents, allowing them to focus on more strategic or complex issues.
As a result, businesses can operate with smaller customer service teams, reducing labor costs and maintaining high levels of service. This not only saves money, but also improves efficiency, as AI agents can handle repetitive tasks faster and more accurately than humans.
2. Scalability and availability
As mentioned earlier, Voice AI offers unmatched scalability. Whether you’re dealing with a sudden spike in customer inquiries or operating across multiple time zones, Voice AI agents ensure no customer is left waiting. They can manage unlimited interactions simultaneously, providing the same level of service to every customer, regardless of demand.
In addition, because Voice AI operates 24/7, businesses no longer need to worry about staffing for off-hours or paying overtime for extended support. This around-the-clock availability ensures that customers can access help whenever they need it, improving overall satisfaction and reducing wait times.
3. Enhanced customer experience
One of the most important factors in customer service is the customer experience, and Voice AI has the potential to dramatically improve it. By offering quick, consistent responses, Voice AI agents eliminate the frustration that comes with long wait times and inconsistent answers from human agents.
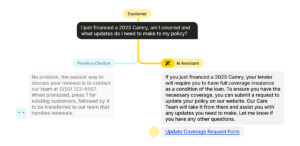
Voice AI can also deliver personalized interactions by integrating with CRM systems and accessing customer data. This allows the AI to address customers by name, understand their preferences, and provide tailored solutions based on their history with the company. The result is a more engaging and satisfying customer experience that leaves customers feeling valued and understood.
4. Multilingual support
For businesses with different cultural customers, Voice AI offers another important advantage: multilingual support. Many Voice AI systems are equipped to handle multiple languages, making it easier for companies to support customers around the world. Voice AI can detect if your customer is speaking another language and translate their response instantaneously. This extraordinarily personalized service can transform your customer’s interactions and prevent many of the issues that come with language barriers. This not only improves accessibility, but also enhances the overall customer experience, as customers can interact with the company in their preferred language.
5. Improved data collection and insights
In addition to its customer-facing benefits, Voice AI also provides businesses with valuable insights into customer behavior. Because AI agents record and analyze every interaction, companies can use this data to identify trends, spot recurring issues, and improve their products or services based on customer feedback.
By understanding what customers are asking for and where they’re encountering problems, businesses can refine their customer support strategy, improve AI performance, and even identify areas where additional human intervention may be needed. This data-driven approach allows CX leaders to make more informed decisions and continuously improve their customer service operations.
Voice AI for CX is just getting started
Looking ahead, the future of Voice AI is full of exciting possibilities. As technology continues to advance, the gap between human and AI interactions will continue to narrow, with Voice AI agents becoming even more capable of handling complex and nuanced conversations.
Future developments in emotional intelligence and predictive capabilities will allow AI agents to not only understand what customers say, but also anticipate what they need before they even ask.
For CX leaders, staying ahead of these developments is crucial. Businesses that invest in a Voice AI platform will be well-positioned to reap the benefits of these advancements as they continue to evolve. By embracing Voice AI as part of a hybrid approach, companies can create a customer service model that combines the efficiency and scalability of AI with the empathy and creativity of human agents.
Voice AI is a game-changer for CX leaders
The rise of Voice AI revolutionizes how businesses approach customer service, offering scalable, cost-effective, and personalized solutions that were once only possible with large teams of human agents. From automating routine tasks to providing real-time, tailored experiences, Voice AI is reshaping customer interactions in ways that improve efficiency and satisfaction.
For CX leaders, the time to embrace Voice AI is now. As this technology continues to evolve, it will become an even more powerful tool for delivering superior customer experiences, optimizing operational processes, and driving long-term success. By integrating Voice AI agents into your customer service strategy, you can balance the speed and consistency of AI with the empathy and creativity of human agents—building a support system that meets the ever-growing demands of today’s customers.
Voice AI is not just a trend, it’s the future of customer service. Staying ahead of the curve now will ensure your business remains competitive in a world where customer expectations continue to rise, and the need for seamless, personalized interactions becomes even more critical.