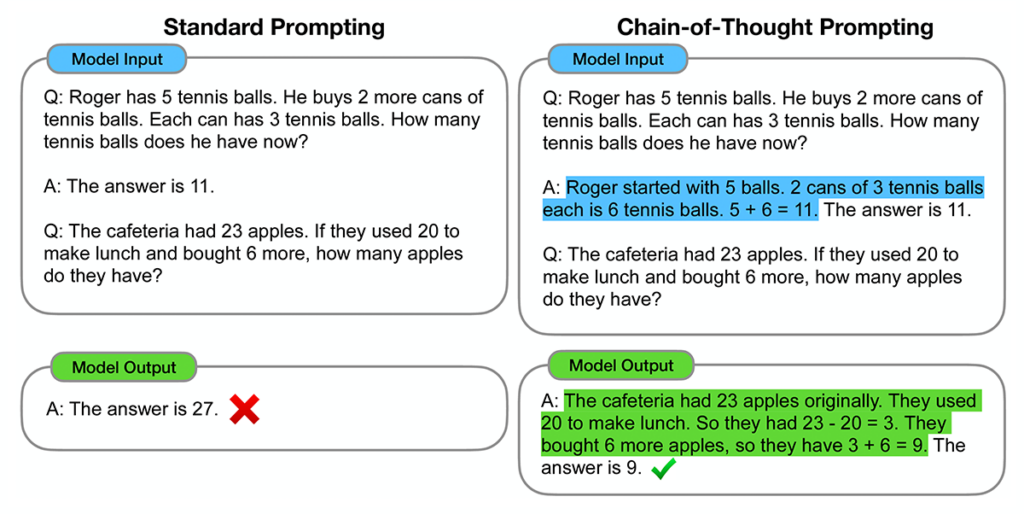
Now that we’ve all seen what ChatGPT can do, it’s natural to begin casting about for ways to put it to work. An obvious place where a generative AI language model can be used is in contact centers, which involve a great deal of text-based tasks like answering customer questions and resolving their issues.
But is ChatGPT ready for the on-the-ground realities of contact centers? What if it responds inappropriately, abuses a customer, or provides inaccurate information?
We at Quiq pride ourselves on being experts in the domain of customer experience and customer service, and we’ve been watching the recent developments in the realm of generative AI for some time. This piece presents our conclusions about what ChatGPT is, the ways in which ChatGPT can be used for customer service, and the techniques that exist to optimize it for this domain.
What is ChatGPT?
ChatGPT is an application built on top of GPT-4, a large language model. Large language models like GTP-4 are trained on huge amounts of textual data, and they gradually learn the statistical patterns present in that data well enough to output their own, new text.
How does this training work? Well, when you hear a sentence like “I’m going to the store to pick up some _____”, you know that the final word is something like “milk”, “bread”, or “groceries”, and probably not “sawdust” or “livestock”. This is because you’ve been using English for a long time, you’re familiar with what happens at a grocery store, and you have a sense of how a person is likely to describe their exciting adventures there (nothing gets our motor running like picking out the really good avocados).
GPT-4, of course, has none of this context, but if you show it enough examples it can learn to imitate natural language quite well. It will see the first few sentences of a paragraph and try to predict what the final sentence is. At first, its answers are terrible, but with each training run its internal parameters are updated, and it gradually gets better. If you do this for long enough you get something that can write its own emails, blog posts, research reports, book summaries, poems, and codebases.
Is ChatGPT the Same Thing as GPT-4?
So then, how is ChatGPT different from GPT-4? GPT-4 is the large language model trained in the manner just described, and ChatGPT is a version fine-tuned using reinforcement learning with human feedback to be good at conversations.
Fine-tuning refers to a process of taking a pre-trained language model and doing a little extra work to narrow its focus to doing a particular task. A generic LLM can do many things, including write limericks; but if you want it to consistently write high-quality limericks, you’ll need to fine-tune it by showing it a few dozen or a few hundred examples of them.
From that point on it will be specialized for limerick production, and might consequently be less useful for other tasks.
This is how ChatGPT was created. After GPT-3.5 or GPT-4 was finished training, engineers did additional fine-tuning work that led to a model that was especially good at having open-ended interactions with users.
What does ChatGPT mean for Customer Service?
Given that ChatGPT is useful for customer interactions, how might it be deployed in customer service? We believe that a good list of initial use cases includes question answering, personalizing responses to different customers, summarizing important information, translating between languages, and performing sentiment analysis.
This is certainly not everything current and future versions of ChatGPT will be able to do for customer service, but we think it’s a good place to start.
Question Answering
Question answering has long been of such interest to machine learning engineers that there’s a whole bespoke dataset specifically for it (the Stanford Question Answering Dataset, or SQuAD).
It’s not hard to see why. Humans can obviously answer questions, but there are so many possible questions that there’s just no way to get to it all. What if you’d like high-level summaries of all the major research papers published about an obscure scientific sub-discipline? What if you’d like to see how the tone of Victorian-era English novels changed over time? There are only so many person-hours that can go toward digging into queries like this.
Customers, too, have many questions, and answering them takes a lot of time. You could collect all the frequently asked questions and put them into a single document for easy reference, but there are still going to be areas of confusion and requests for clarification (and that’s not even considering the fraction of users who never make it to your FAQ page in the first place).
Automating the process of asking questions is an obvious place to utilize technology like ChatGPT. It’ll never get frustrated answering the same thing thousands of times, it’ll never lose its patience, it’ll never sleep, and it’ll never take a bathroom break.
Vanilla ChatGPT is pretty good at doing this already, and there are already many projects focused on getting it to answer questions about a particular company’s documentation.
This functionality will enable you to field an effectively unlimited number of customer questions while freeing up your contact center agents to tackle more important issues.
Onboarding New Hires
Customers are not the only people who might have questions about your product – new hires unfamiliar with your process for doing things might also have their fair share of confusion.
Even in companies that are very conscious about documentation, there can often be so much to get through that new employees – who already have a lot going on – can feel overwhelmed.
A large language model trained to answer questions about your documentation will be a godsend to the fresh troops you’ve brought in.
Summarization
A related task is summarizing email threads, important technical documents, or even videos.
Just as you can’t realistically expect every customer to assiduously look through all your company’s documents, it’s usually not realistic to expect that all of your own employees will do so either.
Here, too, is a place where ChatGPT can be useful. It’s quite good at taking a lengthy bit of text and summarizing it, so there’s no reason it can’t be used to keep your teams up to speed on what’s happening in parts of the organization that they don’t interact with all that often.
If your engineers don’t want to go over an exchange between product designers, or your marketing team doesn’t want all the details of a conversation between the data scientists, ChatGPT can be used to create summaries of these interactions for easier reading.
This way everyone knows what’s going on throughout the company without needing to spend hours every day staying abreast of evolving issues.
At Quiq, we’ve developed proprietary ways to harness ChaGPT’s generative abilities to summarize conversations for your contact center agents.
Sentiment Analysis
Finally, another way in which ChatGPT will power the contact center of the future is with sentiment analysis. Sentiment analysis refers to a branch of machine learning aimed at parsing the overall tone of a piece of text. This can be more subtle than you might think.
“I hate this restaurant” is pretty unambiguous, but what about a review like “Yeah, we loved this restaurant, we had plenty of time to chat because the food took an hour to come out, and since my enchilada was frozen it counteracted my usual inability to eat spicy food”? You and I can hear the implied eye-rolling in this text, but a machine won’t necessarily be able to unless it’s very powerful.
This matters for contact centers because you need to understand how people are talking about your product, whether that’s in online reviews, internal tickets, or during conversations with your agents.
And ChatGPT can help. It’s not only quite good at sentiment analysis, but it’s also better than quite a lot of alternative machine-learning approaches to sentiment analysis, even without fine-tuning.
(Note, however, that these tests compare it to relatively simple machine learning models, not to the very best deep-learning sentiment analyzers.)
Prioritizing Incoming Issues
One way that ChatGPT can add tremendous value to your contact center is in helping to prioritize issues as they come in. There are always lots of problems to solve, but they’re not all equally important. Finding the most pressing issues and marking them for resolution is a huge part of keeping your center running smoothly.
This is something that humans can do, but there’s only so much energy they can devote to this task. A properly trained generative language model, however, can handle a huge chunk of it, especially when it forms part of a broader suite of AI tools.
One way this could work is using ChatGPT for plucking out essential keywords from a customer service ticket. This by itself might be enough to help your contact center agents figure out what they should focus on, but it can be made even better if these words are then fed to a classification algorithm trained to identify urgent problems.
Real-time Language Translation
Language translation, too, is a clear use case for LLMs, and the deep learning upon which they are based has seen much success in translating from one language to another.
This is especially useful if your product or service enjoys a global audience. Many people have a passing familiarity with English but will not necessarily be able to follow a detailed procedure involving technical vocabulary, and that will be a source of frustration for them.
By substantially or totally automating real-time language translation, ChatGPT can help customers who lack English fluency to better interact with your company’s offerings, answering their questions, resolving their issues, and in general moving them along.
And in case you’re wondering, ChatGPT is currently even better than Google Translate or DeepL at most translation tasks, including tricky ones involving jokes and humor.
Fine-Tuning ChatGPT for Customer Service
So far we’ve mostly talked about ChatGPT out of the box, but we’ve also made some references to “fine-tuning” it.
In this section, we’ll flesh out our earlier comments about fine-tuning ChatGPT, and distinguish fine-tuning from related techniques, like prompt engineering.
What is Fine-Tuning ChatGPT?
Once upon a time, it was anyone’s guess as to whether you’d be able to pre-train a single large model on a dataset and then tweak it for particular applications, or whether you’d need to train a special model for every individual task.
Beginning around 2011, it became increasingly clear that for many applications, pre-training was the way to go, and since then, many techniques have been developed for doing the subsequent fine-tuning.
When you fine-tune a pre-trained generative AI model, you are effectively altering its internal structure so that it does better on the task you’re interested in. Sometimes this involves changing the whole model, other times you’re altering the last few output layers and leaving the rest of the model intact.
But what it ultimately boils down to is creating a fine-tuning pipeline through which your model sees a lot of examples of the behavior you’re trying to elicit. If you were fine-tuning it to be more polite in its follow-up questions, for example, you’d need to collect a bunch of examples of this politeness and have your model learn on them.
How many examples you end up needing will depend on your specific use case, but it’s usually a few dozen and could be as many as a few hundred.
How is Fine-Tuning Different From Prompt Engineering?
Prompt engineering refers to the practice of carefully sculpting the prompt you feed your model to do a better job of producing the output you want to see.
The reason this works is that GPT-4 and other LLMs are extremely sensitive to slight changes in the wording of their prompts. It takes a while to develop the feel required to reliably produce good results with an LLM, and all of this falls under the label of “prompt engineering”.
It’s possible to inject some light fine-tuning into prompt engineering, through one-shot and few-shot learning. One-shot learning means including one example of the behavior you want to see in your prompt, and few-shot learning is the same idea, but you’re including 2-5 examples for the LLM to learn from.
FAQs About ChatGPT for Customer Service
Now that we’ve finished our discussion of the basics of ChatGPT for customer service, we’ll spend some time addressing common questions about this subject.
Can I Use ChatGPT for Customer Service?
Yes! ChatGPT is ideal for customer service applications, but you need to fine-tune ChatGPT on your own company’s documentation or to get it to strike the right tone. With the right guardrails, it’s a powerful tool for those looking to build a forward-looking contact center.
What are the Examples of ChatGPT in Customer Service?
ChatGPT can be used for customer service tasks like question answering, sentiment analysis, translating between natural languages, and summarizing documents. These are all time-intensive tasks, the automation of which will free up your contact center agents to focus on higher-priority work.
Can you Automate Customer Service?
Tools like AutoGPT and SuperAGI are making it easier than ever to create and manage sophisticated agents capable of handling open-ended tasks. Still, artificial intelligence is not yet flexible enough to entirely automate customer service at present.
It can be used to automate substantial parts of customer service, like answering user questions, but for the moment the lion’s share of the work must still be done by flesh-and-blood human beings.
If you’re interested in developments in this space, be sure to follow the Quiq blog for updates.
ChatGPT and the Contact Center of the Future
ChatGPT and related technologies are already changing the way contact centers function. From automated translation to helping field dramatically more questions per hour, they are helping contact center agents be more productive and reducing organizational turnover.
The Quiq platform is an excellent tool for incorporating conversational AI into your offering, without having to hire a team or manage your own infrastructure. Quiq can help you automate text messaging, handle real-time translation, and track the performance of your AI Assistants to see where improvements need to be made.