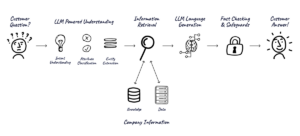
This is the final post in a three-part series clarifying the biggest misconceptions holding CX leaders like you back from integrating GenAI into their CX strategies. Our goal? To assuage your fears and help you start getting real about adding an AI Assistant to your contact center — all in a fun “two truths and a lie” format.
There are few faux pas as damaging and embarrassing for brands as sensitive data getting into the wrong hands. So it makes sense that data security concerns are a major deterrent for CX leaders thinking about getting started with GenAI.
In the first post of our AI Misconceptions series, we discussed why your data is definitely good enough to make GenAI work for your business. Next, we explored the different types of hallucinations that CX leaders should be aware of, and how they are 100% preventable with the right guardrails in place.
Now, let’s wrap up our series by exposing the truth about GenAI potentially leaking your company or customer data.
Misconception #3: “GenAI inadvertently leaks sensitive data.”
As we discussed in part one, AI needs training data to work. One way to collect that data is from the questions users ask. For example, if a large language model (LLM) is asked to summarize a paragraph of text, that text could be stored and used to train future models.
Unfortunately, there have been some famous examples of companies’ sensitive information becoming part of datasets used to train LLMs — take Samsung, for instance. Because of this, CX leaders often fear that using GenAI will result in their company’s proprietary data being disclosed when users interact with these models.
Truth #1: Public GenAI tools use conversation data to train their models.
Tools like OpenAI’s ChatGPT and Google Gemini (formerly Bard) are public-facing and often free — and that’s because their purpose is to collect training data. This means that any information that users enter while using these tools is free game to be used for training future models.
This is precisely how the Samsung data leak happened. The company’s semiconductor division allowed its engineers to use ChatGPT to check their source code. Not only did multiple employees copy/paste confidential code into ChatGPT, but one team member even used the tool to transcribe a recording of an internal-only meeting!
Truth #2: Properly licensed GenAI is safe.
People often confuse ChatGPT, the application or web portal, with the LLM behind it. While the free version of ChatGPT collects conversation data, OpenAI offers an enterprise LLM that does not. Other LLM providers offer similar enterprise licenses that specify that all interactions with the LLM and any data provided will not be stored or used for training purposes.
When used through an enterprise license, LLMs are also Service Organization Control Type 2, or SOC 2, compliant. This means they have to undergo regular audits from third parties to prove that they have the processes and procedures in place to protect companies’ proprietary data and customers’ personally identifiable information (PII).
The Lie: Enterprises must use internally-developed models only to protect their data.
Given these concerns over data leaks and hallucinations, some organizations believe that the only safe way to use GenAI is to build their own AI models. Case in point: Samsung is now “considering building its own internal AI chatbot to prevent future embarrassing mishaps.”
However, it’s simply not feasible for companies whose core business is not AI to build AI that is as powerful as commercially available LLMs — even if the company is as big and successful as Samsung. Not to mention the opportunity cost and risk of having your technical resources tied up in AI instead of continuing to innovate on your core business.
It’s estimated that training the LLM behind ChatGPT cost upwards of $4 million. It also required specialized supercomputers and access to a data set equivalent to nearly the entire Internet. And don’t forget about maintenance: AI startup Hugging Face recently revealed that retraining its Bloom LLM cost around $10 million.

Using a commercially available LLM provides enterprises with the most powerful AI available without breaking the bank— and it’s perfectly safe when properly licensed. However, it’s also important to remember that building a successful AI Assistant requires much more than developing basic question/answer functionality.
Finding a Conversational CX Platform that harnesses an enterprise-licensed LLM, empowers teams to build complex conversation flows, and makes it easy to monitor and measure Assistant performance is a CX leader’s safest bet. Not to mention, your engineering team will thank you for giving them optionality for the control and visibility they want—without the risk and overhead of building it themselves!
Feel Secure About GenAI Data Security
Companies that use free, public-facing GenAI tools should be aware that any information employees enter can (and most likely will) be used for future model-training purposes.
However, properly-licensed GenAI will not collect or use your data to train the model. Building your own GenAI tools for security purposes is completely unnecessary — and very expensive!
Want to read more or revisit the first two misconceptions in our series? Check out our full guide, Two Truths and a Lie: Breaking Down the Major GenAI Misconceptions Holding CX Leaders Back.